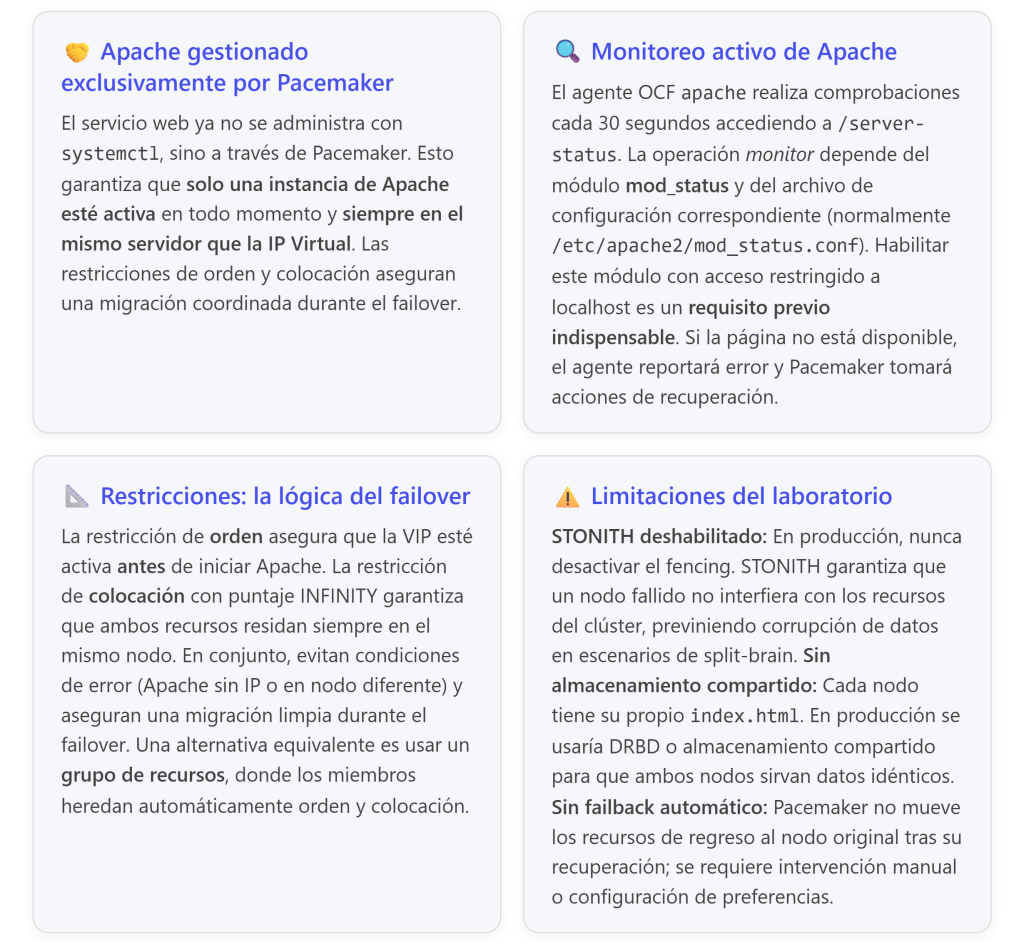
Objetivo: Extender el clúster activo/pasivo previamente configurado para que el servicio Apache2 sea gestionado por Pacemaker, de modo que solo esté activo en el nodo que tiene la IP virtual (VIP), que migre automáticamente junto con la VIP durante un failover, y que el usuario final no perciba la caída.
La siguiente guía asume que ya se cuenta con un clúster Pacemaker+Corosync operativo (según la práctica anterior) y que ya existe un recurso de dirección IP Virtual actualmente activo en nodo-a. Apache aún no está gestionado por el clúster, por lo que será añadido en esta práctica. El DocumentRoot del servidor web es /var/www/html en ambos nodos. En este entorno de laboratorio no se usa DRBD para la replicación de archivos y STONITH está deshabilitado.

Contexto confirmado del laboratorio:
| Elemento | Valor |
|---|---|
| Clúster | Pacemaker + Corosync, ya creado y operativo |
| Recurso IP Virtual | IP-Virtual (ocf:heartbeat:IPaddr2), ya funcional en nodo-a |
| DRBD | No se usa en esta práctica |
| STONITH | Deshabilitado (stonith-enabled=false) — entorno de laboratorio |
| DocumentRoot | /var/www/html |
| Modo | Activo/pasivo (single-primary) |

Paso 1: Instalación de Apache en ambos nodos
Comando (en cada nodo):
apt install -y apache2
Qué se hace: Se instala el servidor web Apache2 en los dos nodos del clúster.
Por qué se hace: Apache debe estar instalado en todos los nodos del clúster para que Pacemaker pueda iniciarlo en cualquiera de ellos si fuera necesario. Si Apache solo estuviera en un nodo, un failover al otro sería imposible: Pacemaker intentaría ejecutar un binario que no existe. Aunque solo un nodo lo ejecutará en cada momento (modelo activo/pasivo), ambos deben tener el software disponible.
Qué ocurre internamente: La instalación deposita los binarios (/usr/sbin/apache2), los archivos de configuración (/etc/apache2/), los módulos disponibles y los scripts de servicio. En Debian, el archivo de configuración principal es /etc/apache2/apache2.conf. Aún no se modifica nada en la pila de red ni en el clúster; solo se prepara la capa de aplicación de cada servidor.
Verificación:
apache2 -v→ muestra la versión instalada.dpkg -l | grep apache2→ confirma que los paquetes están instalados.- El directorio
/var/www/htmldebe existir (creado por la instalación), conteniendo la página predeterminada de Apache.
Errores comunes:
| Problema | Síntoma | Solución |
|---|---|---|
| Repositorios desactualizados | apt no localiza el paquete apache2 | Ejecutar apt update antes de la instalación |
| Permisos insuficientes | Error de permisos al instalar | Ejecutar como root o con sudo |
| Versiones distintas entre nodos | Comportamiento inconsistente tras failover | Mantener el mismo nivel de paquetes en ambos nodos |
Paso 2: Desactivar Apache como servicio del sistema (CRÍTICO)
Comandos (en cada nodo):
systemctl stop apache2
systemctl disable apache2
Verificar:
systemctl is-enabled apache2
Debe responder: disabled.
Qué se hace: Se detiene cualquier instancia de Apache corriendo actualmente y se deshabilita su inicio automático al arrancar el sistema operativo.
Por qué se hace: En un clúster HA, solo Pacemaker debe controlar el inicio y detención de los servicios clusterizados. Sin este paso, Apache podría iniciarse automáticamente en ambos nodos tras un reinicio, generando una situación grave:
- Dos instancias concurrentes del servidor web, potencialmente compitiendo por el puerto 80.
- Conflicto con Pacemaker: al detectar Apache ejecutándose fuera de su control, Pacemaker podría marcar el recurso en estado de error o tomar medidas inesperadas.
- Ruptura del modelo activo/pasivo: el servicio quedaría activo en ambos nodos simultáneamente sin coordinación.
Qué ocurre internamente:stop envía la señal de apagado al proceso Apache si está corriendo. disable elimina los enlaces simbólicos del servicio en los targets de systemd (multi-user.target.wants), impidiendo que Apache se inicie automáticamente al arrancar el sistema. Tras este paso, Apache solo arrancará cuando Pacemaker ejecute la acción start del agente OCF.
Verificación completa:
systemctl status apache2→ inactive (dead) en ambos nodos.systemctl is-enabled apache2→ disabled en ambos nodos.pgrep -f apache2→ sin resultados (no hay procesos Apache).ss -tlnp | grep :80→ sin resultados (el puerto 80 no está en uso).
Errores comunes:
| Problema | Síntoma | Solución |
|---|---|---|
| Apache arranca tras reinicio | systemctl status apache2 muestra active tras un reboot | Verificar que systemctl disable apache2 se ejecutó correctamente en ese nodo. Repetir si es necesario. |
| Olvidar ejecutar en un nodo | Pacemaker inicia Apache en nodo-a, pero Apache ya corre por systemd en nodo-b → puerto 80 ocupado, conflictos de estado | Detener y deshabilitar Apache en todos los nodos. Si Pacemaker ya reporta error, limpiar con pcs resource cleanup Apache. |
| Proceso residual de Apache | pgrep apache2 muestra PIDs tras stop | Verificar con systemctl status apache2 y, si persiste, usar kill para eliminar procesos huérfanos. |
Paso 3: Crear una página de prueba en cada nodo
Comando (en cada nodo):
echo "Apache activo en $(hostname)" > /var/www/html/index.html
Qué se hace: Se crea un archivo index.html con contenido distintivo en cada nodo: en nodo-a quedará «Apache activo en nodo-a» y en nodo-b quedará «Apache activo en nodo-b».
Por qué se hace: Esta página permite identificar visualmente qué nodo está sirviendo las peticiones web en cada momento. Durante el failover, al consultar la IP virtual con curl, la respuesta cambiará de «nodo-a» a «nodo-b», confirmando la migración del servicio. Es una herramienta didáctica fundamental para recolectar evidencias y analizar el comportamiento del clúster.
Qué ocurre internamente: Se escribe un archivo de texto en el sistema de archivos local de cada nodo. Como no se usa DRBD en esta práctica, cada nodo tiene su propio almacenamiento independiente para /var/www/html — los archivos index.html son diferentes a propósito. En un entorno de producción se utilizaría almacenamiento compartido o replicado (como DRBD) para que ambos nodos sirvan exactamente los mismos datos.
Verificación:
- En
nodo-a:cat /var/www/html/index.html→Apache activo en nodo-a. - En
nodo-b:cat /var/www/html/index.html→Apache activo en nodo-b.
Errores comunes:
| Problema | Síntoma | Solución |
|---|---|---|
| Permiso denegado | Error al escribir en /var/www/html/ | Ejecutar con sudo o como root |
| Directorio inexistente | «No such file or directory» | Verificar instalación de Apache; crear con mkdir -p /var/www/html si falta |
| Hostname incorrecto | La página muestra localhost u otro nombre | Confirmar que hostnamectl set-hostname se ejecutó correctamente en cada nodo (paso de la práctica anterior) |
Paso 4: Habilitar mod_status en Apache (Requisito del agente OCF)
⚠️ Este paso no está en la lista original de comandos de la actividad, pero es un requisito técnico indispensable para que el agente OCF
ocf:heartbeat:apachefuncione correctamente. Sin él, el recurso Apache fallará al intentar monitorizar el servicio.
¿Por qué es necesario? El agente de recursos ocf:heartbeat:apache utiliza por defecto la página de estado del servidor (/server-status) para verificar que Apache está operativo. Esta funcionalidad depende del módulo mod_status y del archivo de configuración correspondiente (normalmente /etc/apache2/mod_status.conf). Si la página de estado no funciona o no está restringida exclusivamente a localhost (127.0.0.1), el agente reportará un fallo de monitorización y Pacemaker marcará el recurso como defectuoso.
La documentación oficial del agente OCF indica explícitamente: «Make sure that the server status page works and that the access is allowedonlyfrom localhost (address 127.0.0.1)». Además, si la statusurl responde desde direcciones distintas a localhost, «it may happen that the cluster complains about the resource being active on multiple nodes».
Qué hacer (en ambos nodos):
- Habilitar el módulo mod_status: sudo a2enmod status
- Crear o editar la configuración de server-status. La guía de Server World muestra una configuración funcional para clústeres Pacemaker: sudo nano /etc/apache2/conf-available/server-status.conf
Contenido: Apache Config<Location /server-status>
SetHandler server-status
Require local
</Location> - Activar la configuración: sudo a2enconf server-status
Verificación (verificación temporal — requiere iniciar Apache brevemente):
- Iniciar Apache manualmente para probar:
sudo systemctl start apache2 - Ejecutar:
curl -s -o /dev/null -w "%{http_code}" http://127.0.0.1/server-status→ debe devolver 200. - Ejecutar desde otro equipo:
curl http://<IP_del_nodo>/server-status→ debe ser rechazado (403 Forbidden) o no responder, confirmando que el acceso está restringido a localhost. - Detener Apache tras la prueba:
sudo systemctl stop apache2(Pacemaker será quien lo inicie después).
Consecuencias de omitir este paso: El agente OCF intentará acceder a http://127.0.0.1/server-status durante la operación start y cada 30 segundos durante monitor. Si la página no responde con código 200, el agente reportará fallo. Pacemaker marcará el recurso como Failed e intentará recuperarlo (potencialmente provocando un failover innecesario o dejando Apache permanentemente detenido).
Paso 5: Crear el recurso Apache en Pacemaker
Comando (desde nodo-a):
pcs resource create Apache \
ocf:heartbeat:apache \
configfile=/etc/apache2/apache2.conf \
statusurl="http://127.0.0.1/server-status" \
op monitor interval=30s
Qué se hace: Se registra Apache como un recurso del clúster en el CIB (Cluster Information Base) de Pacemaker, utilizando el agente de recursos OCF ocf:heartbeat:apache. Tras la creación, Pacemaker evaluará en qué nodo iniciarlo e inmediatamente ejecutará la secuencia de arranque.
Análisis de cada parámetro
Apache— Nombre lógico del recurso en el clúster. Se usará en todos los comandos posteriores (pcs resource status Apache, restricciones, etc.).ocf:heartbeat:apache— Agente de recursos OCF dedicado a gestionar servidores web Apache. Este agente opera tanto con Apache versión 1.x como 2.x. Implementa las acciones estándar:start,stop,status,monitor,meta-datayvalidate-all. Pacemaker invoca estas acciones para controlar el ciclo de vida completo de Apache dentro del clúster. ¿Por qué OCF y no systemd? Pacemaker también puede gestionar servicios víasystemd:apache2, pero el agente OCF ofrece una ventaja clave: monitorización inteligente a través de la página de estado HTTP. El agentesystemdsolo verifica si el proceso existe; el agente OCF verifica que Apache realmente responde a peticiones HTTP, detectando fallos funcionales (no solo caídas del proceso).configfile=/etc/apache2/apache2.conf— Ruta al archivo de configuración principal de Apache. El agente lo analiza para derivar valores predeterminados de otros parámetros del recurso (ruta del binario, puerto, archivo PID). Especificar este parámetro es obligatorio en Debian, ya que el valor predeterminado del agente es/etc/httpd/conf/httpd.conf(ruta típica de Red Hat/CentOS). De forma similar, el binario predeterminado del agente es/usr/sbin/httpd, mientras que en Debian es/usr/sbin/apache2. Al apuntarconfigfilea la ruta correcta de Debian, el agente puede derivar las rutas apropiadas para el sistema.statusurl="http://127.0.0.1/server-status"— URL que el agente utilizará para verificar la salud de Apache. Si no se especifica, el agente intenta deducirla del archivo de configuración. Se recomienda fijarla explícitamente. El acceso a esta URL debe estar restringido exclusivamente a127.0.0.1; de lo contrario, el clúster podría interpretar erróneamente que Apache está activo en múltiples nodos simultáneamente. Esto se configuró en el Paso 4.op monitor interval=30s— Cada 30 segundos, Pacemaker ejecutará la acción monitor del agente, que accede a lastatusurlpara confirmar que Apache sigue operativo. Si la comprobación falla, Pacemaker marcará el recurso como defectuoso y aplicará la política de recuperación configurada (reiniciar localmente o hacer failover al otro nodo).
Qué ocurre internamente al crear e iniciar el recurso
- Actualización del CIB: Pacemaker registra el nuevo primitive
Apachecon sus parámetros y operaciones. - Selección de nodo: Pacemaker evalúa en qué nodo iniciar el recurso. Sin restricciones aún definidas, generalmente seleccionará
nodo-a(donde ya reside la IP-Virtual). - Ejecución de start: El agente OCF arranca Apache utilizando la configuración indicada.
- Bucle de verificación: La operación start no finaliza inmediatamente tras lanzar el proceso. En su lugar, entra en un bucle interno donde invoca repetidamente la acción monitor para confirmar que el servidor arrancó y está operativo. Si monitor no tiene éxito dentro del timeout de start, el recurso Apache terminará con un estado de error. Esto garantiza que Pacemaker no declare Apache como «Started» hasta que realmente esté sirviendo peticiones.
- Monitorización continua: Una vez confirmado el arranque, Pacemaker ejecutará monitor cada 30 segundos para detectar cualquier degradación.
La guía de Server World muestra un ejemplo similar de creación de recurso Apache en Pacemaker: pcs resource create website ocf:heartbeat:apache configfile=/etc/apache2/apache2.conf statusurl=http://127.0.0.1/server-status.
Verificación:
pcs status→ debe mostrar el recurso Apache como Started en nodo-a:Full list of resources: IP-Virtual (ocf::heartbeat:IPaddr2): Started nodo-a Apache (ocf::heartbeat:apache): Started nodo-a- En
nodo-a:pgrep -f apache2→ debe devolver PIDs de los procesos Apache (master y workers). - En
nodo-a:ss -tlnp | grep :80→ debe mostrarapache2escuchando en el puerto 80. - En
nodo-b:pgrep -f apache2→ sin resultados (Apache no corre allí).
Errores comunes:
| Problema | Síntoma | Solución |
|---|---|---|
| mod_status no habilitado | Recurso en estado Failed. En logs: error al acceder a la página de estado. La operación monitor depende de mod_status y el archivo de configuración correspondiente. | Completar el Paso 4: a2enmod status, crear configuración de server-status con Require local. Limpiar el error con pcs resource cleanup Apache. |
Ruta de configfile incorrecta | Apache no inicia. El valor predeterminado del agente es /etc/httpd/conf/httpd.conf, que no existe en Debian. | Verificar que configfile apunte explícitamente a /etc/apache2/apache2.conf. |
| Apache ya corriendo por systemd | Conflicto: «Address already in use» en el puerto 80. | Verificar el Paso 2: systemctl stop apache2 && systemctl disable apache2 en ambos nodos. Luego pcs resource cleanup Apache. |
| Timeout de arranque excedido | El agente no logra confirmar el arranque dentro del tiempo límite. El recurso termina con error. | Incrementar el timeout de start: pcs resource update Apache op start timeout=60s. Verificar que server-status responde correctamente. |
| statusurl accesible desde IPs externas | El clúster puede reportar que Apache está activo en múltiples nodos. | Restringir /server-status a Require local en la configuración de Apache (Paso 4). |
Paso 6: Relacionar Apache con la IP Virtual (Restricciones de Orden y Colocación)
Comandos (desde nodo-a):
pcs constraint order IP-Virtual then Apache
pcs constraint colocation add Apache with IP-Virtual INFINITY
Qué se hace: Se crean dos restricciones en Pacemaker para vincular el recurso Apache con el recurso IP-Virtual existente, garantizando que siempre se ejecuten juntos y en el orden correcto.
Restricción de orden: IP-Virtual then Apache
Esta restricción establece que primero debe activarse la IP Virtual y después Apache. Al detener recursos, el orden se invierte: Apache se detiene antes de liberar la IP. De este modo se evita que Apache intente servir páginas en una IP que aún no está asignada al nodo, o que siga sirviendo tras haberse movido la IP a otro nodo.
Consecuencia práctica: Si por alguna razón la IP Virtual no puede iniciarse (p. ej., por un conflicto de red), Apache no arrancará. Esto es deseable: no tiene sentido tener Apache corriendo sin la dirección IP por la que los clientes acceden al servicio.
Restricción de colocación: Apache with IP-Virtual INFINITY
Obliga a que Apache y la IP Virtual se ejecuten siempre en el mismo nodo. El score INFINITY convierte esta regla en obligatoria (no es una preferencia, es un requisito estricto). Si no puede cumplirse, Pacemaker preferirá dejar Apache detenido antes que violarlo.
Consecuencia práctica: Si la IP Virtual migra de un nodo a otro (por failover o intervención manual), Pacemaker automáticamente detendrá Apache en el nodo original y lo reiniciará en el nodo destino, respetando además la restricción de orden (primero asigna la IP, luego arranca Apache).
Efecto combinado de ambas restricciones
| Escenario | Comportamiento |
|---|---|
| Arranque normal | Pacemaker asigna la VIP a un nodo → luego inicia Apache en ese mismo nodo |
| Failover (nodo activo cae) | Pacemaker asigna la VIP al nodo sobreviviente → luego inicia Apache allí |
| VIP no disponible | Apache permanece detenido en todo el clúster |
| Detención ordenada | Pacemaker detiene Apache → luego remueve la VIP |
Nota didáctica: Una alternativa a las restricciones explícitas es agrupar los recursos en un grupo de recursos (resource group). En un grupo, los recursos se inician en el orden en que se añaden y se detienen en orden inverso, y siempre se ejecutan en el mismo nodo. En esta práctica se usan restricciones individuales para que el estudiante comprenda explícitamente cada regla y su efecto.
Verificación:
pcs constraint show→ debe listar:- Orden:
start IP-Virtual then start Apache (kind:Mandatory) - Colocación:
Apache with IP-Virtual (score:INFINITY)
- Orden:
pcs status→ ambos recursos en el mismo nodo (nodo-a).
Errores comunes:
| Problema | Síntoma | Solución |
|---|---|---|
| Nombres de recurso incorrectos | Error «resource not found» al crear la restricción | Usar exactamente los nombres definidos: IP-Virtual y Apache (respetar mayúsculas, minúsculas y guiones). Verificar con pcs resource status. |
| Falta restricción de colocación | Apache arranca en un nodo distinto al de la IP → servicio inaccesible por la VIP | Agregar la restricción de colocación con score INFINITY. |
| Falta restricción de orden | Apache intenta arrancar antes de que la IP esté disponible → posible fallo de arranque o servicio inaccesible temporalmente | Crear la restricción de orden: pcs constraint order IP-Virtual then Apache. |
Paso 7: Verificar el estado del clúster con Apache integrado
Comando:
pcs status
Salida esperada:
Cluster name: laboratorio-ha
...
Online: [ nodo-a nodo-b ]
...
Full list of resources:
IP-Virtual (ocf::heartbeat:IPaddr2): Started nodo-a
Apache (ocf::heartbeat:apache): Started nodo-a
Esto confirma que la IP Virtual y Apache se ejecutan en nodo-a, mientras nodo-b está Online pero sin recursos asignados (en espera).
Prueba funcional del servicio web
Desde un equipo cliente, desde nodo-b, o desde el propio nodo-a:
curl http://192.168.1.100
Respuesta esperada:
Apache activo en nodo-a
Esto confirma que:
- La IP virtual
192.168.1.100está asignada anodo-a. - Apache está operativo bajo el control de Pacemaker y sirviendo la página de prueba.
- Los clientes acceden al servicio web mediante la IP del clúster, independientemente de las IPs físicas de los nodos.
Verificaciones adicionales:
- En
nodo-a:ip addr | grep 192.168.1.100→ debe mostrar la VIP en una interfaz de red. - En
nodo-a:ss -tlnp | grep :80→ confirma que Apache escucha en el puerto 80. - En
nodo-b:pgrep apache2→ sin resultados (Apache no corre allí). - En
nodo-b:ip addr | grep 192.168.1.100→ sin resultados (la VIP no está allí). - Inicia un ping continuo (
ping 192.168.1.100) desde un tercer equipo para medir la interrupción exacta durante el failover del siguiente paso.
Errores comunes:
| Problema | Síntoma | Solución |
|---|---|---|
| Apache en estado Stopped | pcs status muestra Apache detenido | Verificar que IP-Virtual esté Started. Con colocación INFINITY, si la IP no está activa, Apache permanecerá detenido. Iniciar la IP: pcs resource start IP-Virtual. Revisar logs de Pacemaker: journalctl -eu pacemaker. |
| Apache en estado Failed | Recurso marcado como fallido con fail-count | Investigar la causa (pcs resource failcount show Apache). Causas frecuentes: mod_status no habilitado, configfile incorrecto, puerto ocupado. Corregir y limpiar: pcs resource cleanup Apache. |
| curl no responde | Timeout al acceder a la VIP | Verificar que la IP virtual esté asignada (ip addr en nodo-a). Verificar que Apache esté corriendo. Comprobar firewalls: permitir tráfico al puerto 80 e ICMP en los nodos. |
| Respuesta inesperada | curl devuelve la página predeterminada de Apache en vez de la personalizada | Verificar que /var/www/html/index.html contiene el texto correcto. Confirmar el DocumentRoot en /etc/apache2/sites-enabled/000-default.conf. |
Paso 8: Prueba de failover con Apache
La prueba crítica: verificar que ante la caída del nodo principal, el clúster migra automáticamente tanto la IP virtual como Apache al nodo sobreviviente.
Procedimiento
En nodo-a (actualmente activo):
shutdown -h now
Qué ocurre internamente durante el failover
- Detección del fallo (Corosync): Corosync en
nodo-bdetecta la ausencia de heartbeats denodo-a. Tras agotarse el token timeout, declara anodo-acomo offline. - Notificación a Pacemaker: Corosync comunica el evento de fallo a Pacemaker en
nodo-b. Con la configuracióntwo_node: 1(habitual en clústeres de 2 nodos),nodo-bmantiene el quórum y puede operar de forma autónoma. - Coordinación (DC): Si
nodo-aera el Designated Coordinator,nodo-basume ese rol automáticamente. - Migración secuencial (restricción de orden): Pacemaker identifica que
IP-VirtualyApacheestaban activos en el nodo caído y deben recuperarse. Respetando la restricción de orden:- Primero: Asigna la IP Virtual a
nodo-b. El agenteIPaddr2configura la IP192.168.1.100en la interfaz de red denodo-by emite un paquete ARP gratuito para actualizar las tablas ARP de switches/routers. - Después: Inicia Apache en
nodo-b. El agenteocf:heartbeat:apachearranca el servicio y verifica mediante el bucle de monitorización enhttp://127.0.0.1/server-statusque Apache responde correctamente.
- Primero: Asigna la IP Virtual a
- Servicio restaurado: En pocos segundos,
nodo-bes el nodo activo con la VIP y Apache ejecutándose. Los clientes perciben, a lo sumo, uno o dos pings perdidos durante la transición.
Verificación en nodo-b (nuevo activo)
Estado del clúster:
pcs status
Debe mostrar:
Online: [ nodo-b ]
OFFLINE: [ nodo-a ]
...
IP-Virtual (ocf::heartbeat:IPaddr2): Started nodo-b
Apache (ocf::heartbeat:apache): Started nodo-b
Verificar la IP:
ip addr | grep 192.168.1.100
→ Debe mostrar la VIP asignada en la interfaz de nodo-b.
Verificar el servicio web:
curl http://192.168.1.100
→ Respuesta: «Apache activo en nodo-b». La página ahora proviene del segundo nodo, confirmando que tanto la IP como Apache migraron exitosamente.
Comportamiento al retornar nodo-a
Si se enciende de nuevo nodo-a, éste reingresará al clúster (estado ONLINE), pero Pacemaker no revertirá automáticamente los recursos al nodo original. Los recursos permanecen en nodo-b para evitar oscilaciones (ping-pong) en caso de fallas intermitentes. Para migrar los recursos de vuelta a nodo-a, se requiere una orden administrativa (p. ej., pcs resource move) o configurar preferencias de ubicación (resource stickiness, location constraints).
Análisis del tiempo de interrupción
Si se mantuvo un ping continuo a la VIP durante la falla, la cantidad de paquetes perdidos indica la duración aproximada del failover (cada paquete ICMP perdido ≈ 1 segundo con el intervalo predeterminado). En un clúster bien configurado en red local, los clientes perciben a lo sumo una breve pausa. El tiempo exacto depende de:
- Token timeout de Corosync: tiempo que tarda en declarar offline al nodo caído.
- Intervalo de monitorización de Pacemaker: frecuencia con que verifica la salud de los recursos.
- Tiempo de arranque de Apache: cuánto tarda el agente OCF en confirmar que Apache está respondiendo.
Errores comunes:
| Problema | Síntoma | Solución |
|---|---|---|
| Apache no arranca en nodo-b | pcs status muestra Apache en Stopped o Failed en nodo-b | Revisar logs: journalctl -eu pacemaker. Causa más frecuente: mod_status no habilitado en nodo-b. El Paso 4 debe ejecutarse en ambos nodos. Corregir y limpiar: pcs resource cleanup Apache. |
| Failover no ocurre | nodo-b no asume los recursos | Verificar que nodo-b estaba Online antes de apagar nodo-a. Revisar política de quórum: ejecutar pcs property set no-quorum-policy=ignore si el clúster no tiene quórum habilitado para 2 nodos. |
| Interrupción prolongada | Muchos paquetes perdidos durante el failover | Ajustar los timeouts de Corosync y el intervalo de monitorización de Pacemaker. Un intervalo de monitor más corto (ej. 10s) detecta fallos más rápido, pero incrementa la sobrecarga. |
| Inconsistencia por STONITH deshabilitado | Tras reencender nodo-a, Pacemaker detecta conflicto | En laboratorio es infrecuente. Sin STONITH, un nodo que no se apagó limpiamente podría quedar en estado indeterminado. En producción, siempre implementar fencing para evitar que un nodo zombi cause servicios duplicados. |
Tabla Resumen: Comando → Función → Verificación → Error Frecuente
| Paso | Comando(s) | Qué hace | Verificación | Error frecuente |
|---|---|---|---|---|
| 1 | apt install -y apache2 (ambos nodos) | Instala Apache para que pueda ejecutarse en cualquier nodo | apache2 -v muestra versión | Paquete no disponible; versiones distintas entre nodos |
| 2 | systemctl stop apache2; systemctl disable apache2 (ambos) | Detiene y deshabilita Apache en systemd; solo Pacemaker lo controlará | systemctl is-enabled apache2 → disabled | Olvidar deshabilitar en un nodo → doble instancia |
| 3 | echo "Apache activo en $(hostname)" > /var/www/html/index.html (ambos) | Crea página de prueba con hostname para identificar nodo activo | cat /var/www/html/index.html → hostname correcto | Permisos insuficientes; directorio inexistente |
| 4 | a2enmod status; crear server-status.conf; a2enconf server-status (ambos) | Habilita mod_status restringido a localhost, requisito del agente OCF | curl http://127.0.0.1/server-status → código 200 | mod_status no habilitado → agente falla en monitor |
| 5 | pcs resource create Apache ocf:heartbeat:apache configfile=... statusurl=... op monitor interval=30s | Registra Apache como recurso del clúster con monitorización HTTP | pcs status → Apache: Started nodo-a | configfile incorrecto (default es /etc/httpd/conf/httpd.conf) |
| 6 | pcs constraint order IP-Virtual then Apache; pcs constraint colocation add Apache with IP-Virtual INFINITY | VIP se inicia antes que Apache; ambos siempre en el mismo nodo | pcs constraint show lista orden y colocación | Nombres de recurso mal escritos |
| 7 | pcs status; curl http://192.168.1.100 | Confirma estado del clúster y funcionamiento del sitio web | VIP y Apache en nodo-a; curl devuelve «Apache activo en nodo-a» | Apache en Failed → verificar mod_status y logs |
| 8 | shutdown -h now (en nodo-a) | Simula falla del nodo principal; Pacemaker migra VIP + Apache a nodo-b | pcs status → nodo-a OFFLINE, recursos en nodo-b; curl devuelve «Apache activo en nodo-b» | Apache no arranca en nodo-b → verificar mod_status en ambos nodos |