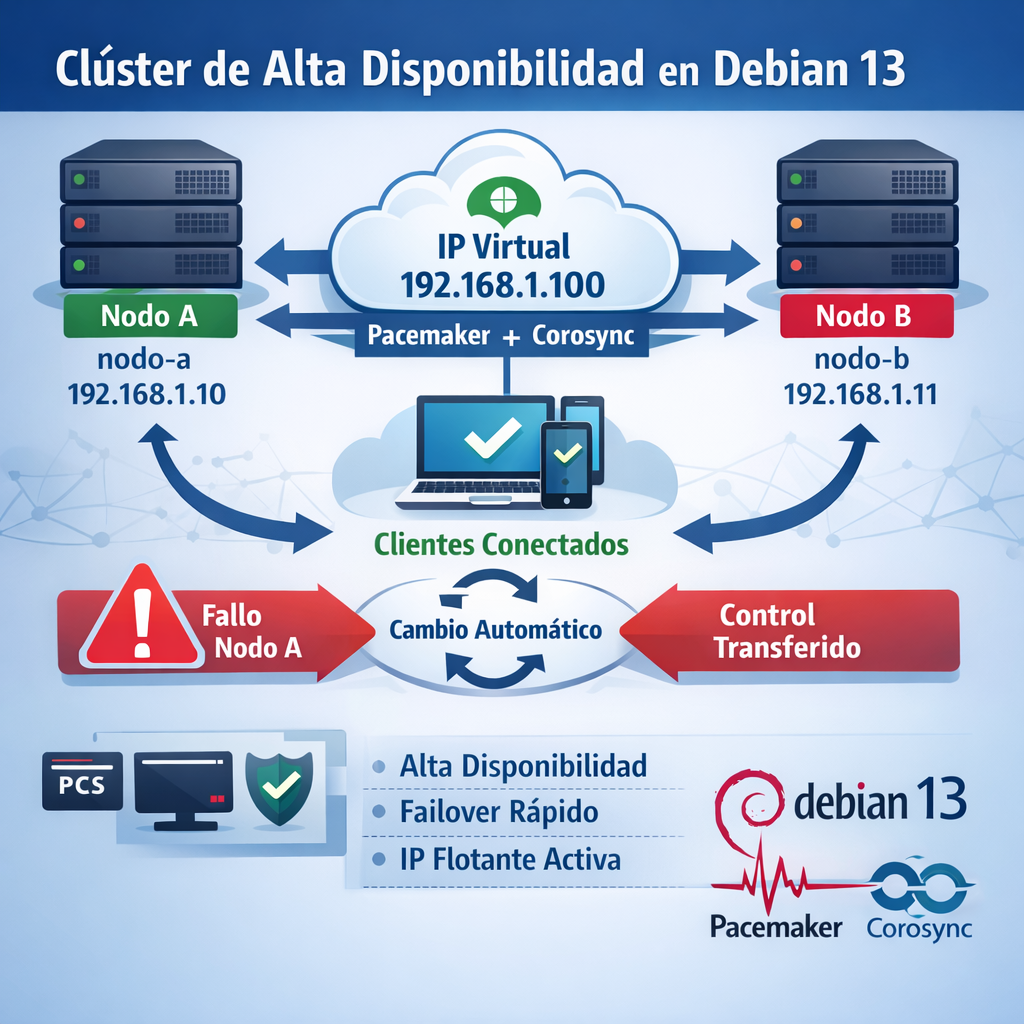
Descripción general: En esta práctica crearemos un clúster de alta disponibilidad (HA) de dos nodos en modo activo/pasivo usando Pacemaker (gestor de recursos de clúster) y Corosync (servicio de comunicación entre nodos) sobre Debian 13. El objetivo es que un recurso (una dirección IP virtual) esté siempre disponible: si el Nodo A falla, el Nodo B tomará automáticamente el control, minimizando la interrupción del servicio (failover). Configuraremos la IP virtual 192.168.1.100 que «flotará» entre los nodos, de modo que los clientes se conecten siempre a esa dirección sin importar qué servidor físico la esté atendiendo.
Se trata de configurar un clúster de alta disponibilidad activo/pasivo en el que uno de los dos equipos pueda responder siempre a la dirección IP que se pretende mantener en alta disponibilidad.
Escenario del laboratorio:
| Elemento | Nodo A | Nodo B |
|---|---|---|
| Hostname | nodo-a | nodo-b |
| IP fija | 192.168.1.10 | 192.168.1.11 |
| IP virtual (VIP) | 192.168.1.100 | (la asume cuando A falla) |
| SO | Debian 13 mínimo | Debian 13 mínimo |
- Ambos nodos están en la misma red local y se puede acceder con privilegios de
root(osudo).
Conceptos clave: Antes de empezar, repasemos los términos esenciales que se usan a lo largo de la práctica:

A continuación se detalla paso a paso la configuración, explicando qué hace cada comando, por qué es necesario y qué ocurre internamente en el clúster. Cada paso incluye verificaciones, posibles errores comunes y cómo identificarlos. Al final se proponen preguntas de análisis y criterios de evaluación.

Paso 1: Preparación de los Nodos (hostname, /etc/hosts, actualización)
Qué se hace: En cada servidor asignamos nombres de host descriptivos, aseguramos la resolución de nombres entre ellos y actualizamos el sistema operativo.
1.1 Cambiar el hostname
En Nodo A:
hostnamectl set-hostname nodo-a
En Nodo B:
hostnamectl set-hostname nodo-b
Esto define el nombre de máquina a nivel del sistema (reflejado en uname -n y hostname). Los nombres de host deben coincidir exactamente con los que usaremos en la configuración del clúster. Pacemaker y Corosync no usan el prompt de la terminal ni apodos; identifican los nodos por su hostname real del SO. Si hay discrepancia (por ejemplo, el hostname del sistema es debian-01 pero en la configuración del clúster se escribe nodo-a), el clúster no reconocerá correctamente a los nodos, provocando errores de autenticación y conectividad. En un entorno de clúster, para cambiar el nombre de una máquina se puede ejecutar hostnamectl set-hostname nombre_nuevo. [blogsaverr…dalucia.es]
1.2 Editar /etc/hosts
En ambos nodos, abrir /etc/hosts:
nano /etc/hosts
Y añadir las siguientes entradas:
192.168.1.10 nodo-a
192.168.1.11 nodo-b
De esta manera, cada nodo puede resolver el nombre del otro por IP. Esto es fundamental porque pcs y Corosync utilizarán los nombres (nodo-a, nodo-b) para establecer la comunicación. Sin resolución correcta, los comandos de autenticación o arranque de clúster fallarán al no poder encontrar el host destino. El blog de maquinasvirtuales.eu muestra un ejemplo de /etc/hosts configurado para un clúster Pacemaker, donde cada nodo tiene su IP y nombre mapeados correctamente.
1.3 Actualizar el sistema
En ambos nodos:
apt update && apt upgrade -y
Mantener Debian actualizado garantiza versiones compatibles de Pacemaker, Corosync y PCS. Tras una actualización que incluya kernel nuevo, es recomendable reiniciar los nodos antes de continuar.
Verificación:
hostnameouname -nen cada nodo → debe mostrarnodo-aonodo-brespectivamente.ping -c 1 nodo-bdesde nodo-a → debe resolver a 192.168.1.11 y responder; lo mismo desde nodo-b hacia nodo-a.- Confirmar que no hay conflictos en
/etc/hosts: no añadirnodo-aen la línea de 127.0.0.1 (pues el clúster intentaría comunicarse consigo mismo).
Errores comunes:
| Problema | Síntoma / Mensaje | Solución |
|---|---|---|
| Hostname no cambiado | pcs indica «no configuration for host X» o el nombre no aparece en pcs status. | Verificar con uname -n. Si no coincide, reejecutar hostnamectl set-hostname y reiniciar la sesión. |
| Resolución de nombres fallida | pcs host auth se cuelga o muestra error de conexión/refused hacia nodo-b. | Verificar las entradas en /etc/hosts de ambos nodos. Probar ping nodo-b desde nodo-a. |
| Firewall bloquea puertos de clúster | Un nodo aparece OFFLINE en pcs status tras configurar el clúster. | Asegurar que el firewall permite tráfico UDP 5404/5405 (puertos estándar de Corosync). En laboratorio, ufw disable o abrir reglas específicas. |
Paso 2: Instalación del Stack de Clúster (Pacemaker, Corosync, PCS)
Qué se hace: Se instalan en ambos nodos los tres componentes del stack de HA:
apt install -y pacemaker corosync pcs
Este comando instala: [linuxmind.dev]
- Pacemaker: el gestor de clúster HA. Se encarga de la gestión de recursos, asegurando que los servicios críticos se mantengan en funcionamiento incluso en caso de fallos de nodo.
- Corosync: la capa de comunicación y consenso entre nodos (anillo o multicast/unicast).
- PCS (Pacemaker/Corosync Configuration System): herramienta de línea de comandos (y GUI) para configurar y administrar clústeres basados en Pacemaker. Permite a los usuarios ver, modificar y crear clústeres fácilmente. PCS incluye un demonio llamado
pcsdque opera como servidor remoto para pcs.
Tras la instalación, habilitamos y arrancamos PCSD en cada nodo:
systemctl enable pcsd
systemctl start pcsd
pcsd escucha en cada nodo y permite que, al autenticarse, podamos ejecutar comandos de configuración del clúster en todos los nodos desde uno solo.
Por qué se hace: Pacemaker y Corosync forman el motor del clúster HA. Sin Pacemaker no habría orquestación de recursos; sin Corosync no habría detección de fallos entre nodos. La herramienta pcs simplifica enormemente la configuración, evitando la edición manual de archivos XML o configuración de Corosync; además, distribuye automáticamente las claves de autenticación a todos los nodos. Habilitar pcsd lo hace persistente tras reinicios.
Internamente:
- Se instalan los servicios systemd
pacemaker,corosyncypcsd, pero aún no se inician Pacemaker ni Corosync — primero debemos completar la autenticación y definición del clúster. Solopcsdse inicia ahora para poder usarpcs. - Corosync maneja un anillo de comunicación (por defecto, UDP unicast —UDPU— cuando se configura con
pcs cluster setup) para enviar mensajes de heartbeat. Para un clúster de dos nodos, es necesario añadirtwo_node: 1en el bloque de quórum de Corosync;pcs cluster setuplo configura automáticamente.
Componentes internos de Pacemaker que conviene conocer:
- CIB (Cluster Information Base): Almacena la configuración y el estado del clúster, replicándolos en todos los nodos para mantener coherencia.
- Resource Agents: Scripts que encapsulan el conocimiento necesario para gestionar un recurso específico (iniciar, detener, monitorizar).
- CRM (Cluster Resource Manager): Toma decisiones sobre la gestión de recursos basadas en la información del CIB y las políticas configuradas.
- Fencing: Mecanismo para aislar un nodo defectuoso del resto del clúster y asegurar la integridad de los datos.
Verificación:
systemctl status pcsd→ debe mostrarlo active (running) en ambos nodos.pcs --version→ muestra la versión instalada de PCS.corosync -v→ muestra la versión de Corosync.- No iniciar aún Pacemaker/Corosync manualmente; lo haremos con
pcstras definir el clúster.
Errores comunes:
| Problema | Síntoma / Mensaje | Solución |
|---|---|---|
| Repositorios faltantes | apt no encuentra paquetes pacemaker o pcs. | Asegurarse de tener los repositorios de Debian 13 correctos en /etc/apt/sources.list. |
| Permisos insuficientes | Error de permisos al instalar. | Ejecutar como root o con sudo. |
pcsd no habilitado | Al intentar autenticación, pcs responde «Error: unable to connect to node…». | Verificar que pcsd está activo en ambos nodos (systemctl status pcsd). Iniciar/habilitar si es necesario. |
| Versiones distintas entre nodos | Errores de protocolo o incompatibilidad durante la autenticación. | Usar la misma versión de paquetes en ambos nodos (mismo SO y actualizaciones). |
Paso 3: Autenticación del Clúster (usuario hacluster y pcs host auth)
Qué se hace: Para que pcs pueda controlar ambos nodos de forma remota, se usa un usuario dedicado llamado hacluster (creado automáticamente al instalar pcs). Se realizan dos tareas:
3.1 Asignar contraseña al usuario hacluster
En cada nodo (ambos):
passwd hacluster
Elegir una contraseña (se recomienda la misma en ambos para simplificar el proceso de autenticación). Este usuario es el que pcs utiliza internamente para autenticarse contra los nodos del clúster.
3.2 Autenticación entre nodos
Desde nodo-a:
pcs host auth nodo-a nodo-b
Este comando establece la confianza mutua entre nodo-a y nodo-b. pcs solicita las credenciales del usuario hacluster y las usa para crear una relación de confianza segura entre ambos nodos. Si pide confirmación de huella digital (fingerprint), aceptar con «yes».
Por qué se hace: Sin autenticación, pcs solo puede administrar el nodo local. Este paso habilita la gestión centralizada: al crear el clúster o recursos, la configuración se propagará automáticamente a ambos nodos. pcs host auth realiza un intercambio de claves de autenticación seguras entre los nodos.
Internamente:pcs host auth realiza conexiones HTTPS al demonio pcsd de cada nodo peer, autenticándose con las credenciales de hacluster. Tras la autenticación exitosa, distribuye los archivos de claves de autenticación de Corosync y Pacemaker. En la salida del comando se observan mensajes como:
Sending 'corosync authkey', 'pacemaker authkey' to 'nodo-a', 'nodo-b'
nodo-a: successful distribution of the file 'corosync authkey'
nodo-a: successful distribution of the file 'pacemaker authkey'
nodo-b: successful distribution of the file 'corosync authkey'
nodo-b: successful distribution of the file 'pacemaker authkey'
Esto confirma que las claves de autenticación de Corosync y Pacemaker se transfirieron y propagaron exitosamente a ambos equipos.
Verificación:
- El comando
pcs host authdebe terminar con un mensaje de éxito para cada nodo (ej.: «nodo-a: Authorized», «nodo-b: Authorized»). - Confirmar desde nodo-b que también reconoce a nodo-a como parte del clúster.
Errores comunes:
| Problema | Síntoma / Mensaje | Solución |
|---|---|---|
| Contraseña distinta o no establecida | pcs host auth falla en uno de los nodos (error de autenticación). | Asegúrate de asignar la misma contraseña en ambos nodos. Repetir passwd hacluster si es necesario. |
| Hostname no resoluble | Error: «Unable to authenticate to host nodo-b» | Revisar resolución de nombres (Paso 1). Alternativamente, usar IPs directamente, aunque lo ideal es que los nombres funcionen. |
pcsd no corriendo en el nodo destino | Error de conexión rechazada. | Verificar systemctl status pcsd en ambos nodos. |
| Relojes desincronizados | Problemas SSL o certificados inválidos. | Verificar que la hora/fecha de ambos nodos sea correcta y esté sincronizada (recomendable usar NTP/Chrony) [linuxmind.dev]. |
Paso 4: Creación y Arranque del Clúster (pcs cluster setup/start/enable)
Qué se hace: Ahora que los nodos confían entre sí, definimos el clúster e iniciamos todos los servicios. Desde nodo-a ejecutamos tres comandos en secuencia:
4.1 Crear el clúster
pcs cluster setup laboratorio-ha nodo-a nodo-b
Esto configura un nuevo clúster con nombre «laboratorio-ha» integrado por los dos nodos especificados. Internamente, pcs realiza varias acciones de una sola vez:
- Genera la configuración de Corosync: incluye el nombre del clúster, el transporte de red (UDPU —unicast UDP— por defecto), la lista de nodos (
nodo-a,nodo-bcon sus IPs correspondientes) y la clave de autenticación para cifrar el tráfico. Esta configuración se almacena en/etc/corosync/corosync.conf. - Distribuye la configuración a ambos nodos: gracias a la autenticación del Paso 3,
pcscopia automáticamente todos los archivos necesarios.
En la salida del comando se observan mensajes similares a los del paso de autenticación, confirmando la distribución exitosa de archivos de configuración y claves a ambos nodos.
4.2 Iniciar el clúster
pcs cluster start –all
Arranca los servicios Corosync y Pacemaker en ambos nodos simultáneamente.
4.3 Habilitar inicio automático
pcs cluster enable –all
Configura que los servicios de clúster inicien automáticamente tras un reinicio del sistema en ambos nodos.
4.4 Verificar estado
pcs status
Por qué se hace:pcs cluster setup nos ahorra editar manualmente archivos XML o de Corosync y garantiza que ambos nodos tengan la misma configuración. Nombrar al clúster ayuda a identificarlo en entornos con múltiples clústeres. Arrancar y habilitar el clúster pone en funcionamiento la infraestructura HA: Corosync establece el enlace de comunicación y Pacemaker espera instrucciones (todavía no hay recursos, los añadiremos en el siguiente paso).
Internamente (qué ocurre al arrancar):
- Corosync inicia su anillo: Los dos nodos establecen comunicación UDP (unicast por defecto al usar
pcs). Se intercambian mensajes de heartbeat y forman un quórum. En un clúster de dos nodos, Corosync habilita automáticamente el modotwo_node: 1, permitiendo al nodo sobreviviente continuar operando aunque el otro caiga. - Pacemaker inicia en cada nodo: Uno de los nodos es elegido como DC (Designated Coordinator), el nodo líder que coordina las decisiones de gestión de recursos (no confundir con «Primary» a nivel de recurso individual). Ambos nodos reportan su estado («Online») al CIB. Puedes identificar el DC en la salida de
pcs status(ej.:Current DC: nodo-a). - Al no tener recursos aún, Pacemaker simplemente mantiene el estado. Ambos nodos aparecen Online y no hay recursos configurados.
Verificación:
pcs statusdebe mostrar 2 nodos online. La sección de nodos indicará algo como:Online: [ nodo-a nodo-b ].- Puede aparecer una advertencia: «WARNINGS: No stonith devices and stonith-enabled is not false». Esto es esperado y se resolverá en el Paso 5.
- Debe figurar «No resources» o una lista vacía de recursos.
- Otra herramienta de verificación:
crm_mon -1muestra información similar de nodos online y recursos.
Errores comunes:
| Problema | Síntoma / Mensaje | Solución |
|---|---|---|
| Fallo en setup | pcs cluster setup lanza errores al conectar con el nodo remoto o copiar archivos. | Asegurarse de haber completado el Paso 3 (auth). Verificar que pcsd esté corriendo en ambos. |
| Nodo aparece OFFLINE | En pcs status, uno de los dos nodos figura OFFLINE. | Verificar en ese nodo: systemctl status corosync y journalctl -xe para ver errores (auth key inválida, firewall, problemas de red). Reintentar pcs host auth y luego pcs cluster start --all. |
| Error HTTP 400 | Corosync no arranca (posible en contenedores LXC o entornos restringidos). | Verificar que el entorno de virtualización permita los servicios necesarios. En LXC Proxmox se requieren parámetros adicionales de configuración del contenedor. |
| Cluster ya existe | Error: «Cluster already exists». | Si necesitas repetir, primero destruye el clúster previo con pcs cluster destroy --all en ambos nodos (esto borra la configuración completa). Luego reintenta setup. |
Paso 5: Configuración de la IP Virtual en Pacemaker (Recurso IPaddr2 y STONITH)
Con el clúster en marcha, añadiremos el primer recurso: una dirección IP flotante gestionada por Pacemaker.
Qué se hace: Desde nodo-a, ejecutamos los siguientes comandos:
5.1 Crear el recurso de IP virtual
pcs resource create IP-Virtual ocf:heartbeat:IPaddr2 ip=192.168.100.100 cidr_netmask=24 op monitor interval=30s
⚠️ Advertencia crítica (discrepancia de IP): El comando anterior usa la IP
192.168.100.100(subred192.168.100.x), pero el escenario del laboratorio define a los nodos en la subred192.168.1.x(IPs192.168.1.10y192.168.1.11) con VIP192.168.1.100. Esto es un error tipográfico en la actividad original. Para que la VIP funcione correctamente en la misma subred que los nodos, el parámetro debería serip=192.168.1.100. Si se usa192.168.100.100, la IP flotante quedará en una subred diferente y no será accesible desde equipos en la red192.168.1.x. Antes de ejecutar este comando, verifica con el docente cuál es la IP correcta.
Desglose del comando:
pcs resource create <nombre> <agente> <parámetros> op monitor <intervalo>— estructura estándar para crear un recurso en Pacemaker.IP-Virtual— nombre lógico del recurso (descriptivo, sin espacios).ocf:heartbeat:IPaddr2— el agente OCF (Open Cluster Framework) utilizado. Pacemaker emplea agentes OCF para controlar servicios.IPaddr2(de la colección heartbeat) gestiona direcciones IP flotantes: sabe asignarla a una interfaz de red, verificar su estado y removerla. Otros ejemplos de agentes OCF incluyenocf:linbit:drbdpara replicación de bloques ysystemd:apache2para servidores web.ip=192.168.1.100(o la IP que corresponda) — dirección IP flotante a gestionar.cidr_netmask=24— máscara de subred en formato CIDR (24 equivale a 255.255.255.0). Opcionalmente, podríamos indicar la interfaz de red connic=<nombre_iface>(por defecto, el agente elige una interfaz en la red de la IP dada).op monitor interval=30s— Pacemaker ejecutará una acción de monitorización cada 30 segundos para verificar que la IP sigue asignada. Si la IP desapareciera (por error humano o fallo de interfaz), Pacemaker lo detectaría en ese intervalo e intentaría recuperarla.
5.2 Deshabilitar STONITH (solo laboratorio)
pcs property set stonith-enabled=false
5.3 Habilitar y arrancar el recurso
pcs resource enable IP-Virtual
pcs resource start IP-Virtual
5.4 Verificar
pcs status
Explicación de STONITH y por qué se desactiva:
STONITH (Shoot The Other Node In The Head) es el mecanismo de fencing más común en clústeres Pacemaker. Su función es aislar o «matar» un nodo defectuoso para que no pueda interferir con los recursos del clúster, previniendo corrupción de datos. Si un nodo falla pero aún «cree» estar activo, podría continuar accediendo a recursos compartidos de forma descontrolada.
Existen distintos tipos de fencing:
- Power fencing: vía IPMI, iLO, DRAC (apaga el nodo por hardware).
- Storage fencing: bloquea el acceso al almacenamiento compartido (ej. SBD).
- Software fencing: detiene servicios o máquinas virtuales.
¿Por qué se desactiva en laboratorio? Porque no disponemos de hardware de fencing (IPMI, iLO, etc.) en un entorno académico. Pacemaker, por defecto, se niega a iniciar recursos si no hay un dispositivo STONITH configurado — muestra la advertencia «No stonith devices and stonith-enabled is not false». Al establecer stonith-enabled=false, silenciamos esta restricción y permitimos que los recursos arranquen.
Riesgo en producción: Desactivar STONITH elimina la última línea de defensa contra situaciones de split-brain (dos nodos que creen ser el activo simultáneamente). En entornos de producción, siempre se debe implementar un mecanismo de fencing adecuado. La guía de Junta de Andalucía lo explica como desactivar STONITH «para parar un nodo que esté dando problemas y así evitar un comportamiento inadecuado del clúster».
Internamente (qué ocurre al crear el recurso):
- Pacemaker actualiza el CIB con un nuevo primitive llamado
IP-Virtual. Inmediatamente evalúa en qué nodo iniciarlo. - Sin restricciones de ubicación, cualquier nodo es candidato. Normalmente, Pacemaker iniciará el recurso en el primer nodo Online disponible (generalmente
nodo-a). - El agente
IPaddr2ejecuta internamente:- Agrega la IP al interfaz de red del nodo seleccionado mediante herramientas del sistema (ej.
ip addr add). - Publica un mensaje ARP gratuito (gratuitous ARP) para que los switches/routers actualicen sus tablas (la MAC de la IP .100 ahora es la de nodo-a).
- Cada 30 segundos, verifica que la IP sigue presente en la interfaz.
- Agrega la IP al interfaz de red del nodo seleccionado mediante herramientas del sistema (ej.
- Pacemaker marca el recurso como Started en el nodo correspondiente.
Verificación:
pcs statusdebe mostrar:Full list of resources: IP-Virtual (ocf::heartbeat:IPaddr2): Started nodo-aSi en lugar de «Started» aparece «Stopped» o «Failed», revisa los errores comunes.pcs resource statusmuestra el estado del recurso de forma más concisa.- Comprobar en
nodo-aque la IP está asignada:ip addr show→ debe listar192.168.1.100(o la IP configurada) como dirección secundaria en la interfaz de red. Ej.:ip addr | grep 192.168.1.100debe devolver una línea con la IP. - Desde un tercer equipo o desde nodo-b:
ping -c 3 192.168.1.100→ debe responder.
Errores comunes:
| Problema | Síntoma / Mensaje | Solución |
|---|---|---|
| IP en subred incorrecta | El recurso se marca Started pero no responde al ping desde la red de los nodos. | Verificar que la IP del recurso esté en la misma subred que las IPs de los nodos (192.168.1.x). Si se usó 192.168.100.100 por error, recrear el recurso con la IP correcta. |
| IP duplicada en la red | Conflicto de ARP: otra máquina ya tiene esa IP. | Elegir una IP libre, no asignada a ningún equipo de la red. Verificar con arping -D <IP>. |
| STONITH no deshabilitado | Recurso Stopped con warning de fencing. | Ejecutar pcs property set stonith-enabled=false antes de crear/arrancar recursos. Verificar con pcs property list. |
| NIC incorrecta | El recurso falla si no encuentra una interfaz adecuada en la red de la IP. | Especificar nic=<nombre_iface> al crear el recurso (ej. nic=ens33). |
| Recurso en nodo-b en vez de nodo-a | No es un error; Pacemaker decidió libremente. | Es válido. Para forzar la ubicación inicial, se puede crear una restricción de ubicación preferencial con pcs constraint location. |
Paso 6: Verificar el Funcionamiento en Nodo Activo
Con el clúster completamente operativo, confirmamos que todo funciona correctamente antes de proceder a la prueba de failover.
6.1 Estado global del clúster
Ejecutar pcs status. Se espera:
- Cluster name: laboratorio-ha.
- Nodes:
nodo-aOnline,nodo-bOnline. - Resources:
IP-Virtual (ocf::heartbeat:IPaddr2)corriendo ennodo-a. - Sin warnings activos (STONITH ya desactivado).
6.2 Comprobar IP en el nodo activo
En nodo-a:
ip addr | grep 192.168.1.100
Debería mostrar la IP asociada a la interfaz de red como dirección secundaria. Ejemplo:
inet 192.168.1.100/24 scope global secondary eth0
Esto confirma que el agente IPaddr2 asignó exitosamente la VIP al nodo activo.
6.3 Prueba de conectividad desde otro equipo
Desde un equipo externo en la misma red o desde nodo-b:
ping 192.168.1.100
La VIP debe responder. Resulta especialmente útil iniciar un ping continuo (ping -t en Windows o ping sin -c en Linux) para medir la interrupción exacta durante el failover del siguiente paso.
Estado esperado: El VIP está atendido por nodo-a. Los clientes usan 192.168.1.100 para acceder al servicio. nodo-b está en espera (standby), con Pacemaker ejecutándose pero sin recursos asignados.
Problemas potenciales:
- Si el ping no responde pero
pcs statusmuestra el recurso Started: verificar que los nodos y el equipo de prueba están en la misma subred, y que no hay firewalls bloqueando ICMP. - Si ambos nodos mostraran la IP simultáneamente, significaría un error grave de configuración (esto no debería ocurrir, ya que Pacemaker nunca iniciará el mismo recurso en dos nodos a la vez en modo single-instance).
Paso 7: Prueba de Failover – Simulación de Caída del Nodo A
La prueba clave de la práctica: verificamos que la alta disponibilidad funciona en la práctica.
Qué se hace: Apagamos el nodo activo y observamos la transferencia automática del recurso al nodo secundario.
En nodo-a:
shutdown -h now
Esto simula un fallo catastrófico del nodo principal. Alternativamente, se puede apagar directamente la máquina virtual (Power off) para emular una caída abrupta.
Qué ocurre internamente durante el failover:
El proceso sigue la secuencia de detección-decisión-acción que define la interacción entre Corosync y Pacemaker:
- Detección del fallo (Corosync): Corosync en
nodo-bdetecta que dejó de recibir mensajes de heartbeat denodo-a. Tras el token timeout configurado, declara anodo-acomo offline en el clúster. Corosync configura y gestiona la comunicación entre los nodos del clúster y detecta cuándo un nodo falla. - Notificación a Pacemaker: Corosync comunica el evento de fallo a Pacemaker en
nodo-b.nodo-bahora tiene el quórum (modotwo_node: 1). - Elección de DC: Si
nodo-aera el Designated Coordinator,nodo-basume ese rol automáticamente. - Recuperación del recurso: Pacemaker en
nodo-bve que el recursoIP-Virtualya no está activo (el nodo que lo tenía ha desaparecido). Decide ejecutar la acción start del agenteIPaddr2ennodo-bpara mantener la disponibilidad del servicio. Pacemaker recibe la información de fallo de Corosync y toma decisiones sobre cómo reubicar los recursos, ejecutando las acciones necesarias para recuperarlos en otros nodos. - ARP Anuncio: Al iniciarse la IP en
nodo-b, el agenteIPaddr2envía un gratuitous ARP para actualizar a los switches y routers: la IP .100 ahora corresponde a la MAC denodo-b.
Todo este proceso ocurre rápidamente. En un ping continuo se observará la pérdida de quizás uno o dos paquetes durante la transición, tras lo cual el servicio se restablece desde nodo-b.
Verificación del failover en nodo-b:
- Ejecutar
pcs statusennodo-b:Cluster name: laboratorio-ha ... Online: [ nodo-b ] OFFLINE: [ nodo-a ] ... IP-Virtual (ocf::heartbeat:IPaddr2): Started nodo-bEsto indica que solonodo-bestá en línea y la IP virtual está corriendo en él. - Comprobar la interfaz de red: Shellip addr | grep 192.168.1.100
Mostrar más líneas Debe mostrar la VIP asignada en la interfaz denodo-b. - Si se mantenía un ping continuo desde un tercer equipo: Se observarán quizás uno o dos paquetes sin respuesta durante la transición, luego el ping se reanuda normalmente. La MAC en la tabla ARP del cliente habrá cambiado de nodo-a a nodo-b.
- Verificar la web o servicio (en prácticas posteriores con Apache): Shellcurl http://192.168.1.100
Mostrar más líneas La respuesta debe provenir ahora denodo-b.
Qué ve el usuario final: El cliente final nota poca o ninguna interrupción. Si la VIP alojara un servidor web (que se configurará en la siguiente práctica), quizás la página tardaría un par de segundos extra, pero luego seguiría funcionando. El usuario no necesita cambiar la IP, porque sigue siendo 192.168.1.100, independientemente de qué nodo la atienda.
Comportamiento al retornar nodo-a: Si se enciende de nuevo nodo-a, éste reingresará al clúster (estado ONLINE), pero Pacemaker no revierte automáticamente el recurso al nodo original (para evitar vaivenes innecesarios). El recurso permanece en nodo-b a menos que se fuerce una migración manual (pcs resource move IP-Virtual nodo-a). Si se desea que el recurso regrese automáticamente al nodo preferido tras su recuperación, se puede configurar la propiedad resource-stickiness de Pacemaker.
Errores comunes / Situaciones a monitorear:
| Problema | Síntoma / Mensaje | Solución |
|---|---|---|
| El failover no ocurre | nodo-b no asumió el recurso tras apagar nodo-a. | Puede deberse a política de quórum restrictiva. Verificar que en un clúster de 2 nodos, Pacemaker tiene habilitado two_node: 1. Si es necesario, ejecutar pcs property set no-quorum-policy=ignore. |
| Recurso queda Stopped | En pcs status de nodo-b, el recurso aparece Stopped en vez de Started. | Revisar logs: journalctl -u pacemaker -e. Puede haber un error del agente (ej. la interfaz de red de nodo-b no está en la misma subred). |
| Ping no vuelve después del failover | Pérdida de paquetes persistente tras la migración. | Verificar que el agente IPaddr2 generó el ARP gratuito. Comprobar ip addr en nodo-b. Posible problema de switch o caché ARP en el cliente (arp -d 192.168.1.100 en el cliente para forzar actualización). |
Paso 8: Análisis y Conclusiones para el Estudiante
Tras observar un failover exitoso (la IP virtual pasó de nodo-a a nodo-b con mínima interrupción), es momento de analizar el comportamiento y responder preguntas clave:
Preguntas de análisis
¿Qué servicio detectó la falla de nodo-a y cómo?Corosync detectó la caída mediante la ausencia de mensajes de heartbeat. Al vencer el token timeout sin respuesta de nodo-a, Corosync indicó la pérdida del nodo en el anillo de comunicación y se lo comunicó a Pacemaker. En resumen: Corosync configura y gestiona la comunicación entre los nodos del clúster, detecta cuándo un nodo falla y comunica este evento a Pacemaker; Pacemaker recibe la información y toma decisiones sobre cómo reubicar los recursos.
¿Cuánto tiempo tardó el failover? Si se realizó un ping continuo, la cantidad de paquetes perdidos indica la duración aproximada. Cada paquete ICMP perdido representa ~1 segundo (intervalo estándar). Un clúster bien configurado en red local logra failovers suficientemente rápidos para que el usuario perciba, a lo sumo, una breve pausa. El tiempo exacto depende de parámetros de Corosync (token timeout) y de Pacemaker (intervalo de monitorización).
¿Por qué el usuario final no necesita cambiar la IP? Porque se implementó una IP virtual flotante que pertenece al clúster, no a un servidor fijo. Antes del fallo, la VIP estaba en nodo-a; después, en nodo-b, pero sigue siendo la misma dirección. Los mecanismos de red (ARP) y Pacemaker redirigieron automáticamente esa IP al nodo sobreviviente. Para el cliente, la dirección nunca cambió.
¿Qué pasaría si ambos nodos fallan? La alta disponibilidad protege contra fallos individuales, no contra la caída total del clúster. Si ambos nodos fallan, no hay ningún equipo para mantener la IP virtual ni los servicios — se produce una interrupción completa hasta que al menos un nodo se recupere. Este escenario requiere planificación de disaster recovery a nivel geográfico, que es una temática diferente. En nuestro clúster de 2 nodos, no hay tolerancia a la caída simultánea de ambos.
Evidencias solicitadas
Para documentar la práctica, se solicitan capturas de:
- Salida de
pcs status— antes y después del failover: ambos nodos online con el recurso en nodo-a inicialmente, luego nodo-a OFFLINE con el recurso en nodo-b. - IP virtual en nodo-b — resultado de
ip addren nodo-b tras el failover, donde se vea la VIP asignada. - Ping continuo durante el failover — captura que evidencie que el ping a la VIP se mantuvo y quizás perdió solo uno o dos paquetes durante la transición.
Extensiones (para profundizar)
Para alumnos avanzados o para continuar la práctica:
- Agregar Apache o Nginx como recurso: Configurar un servidor web gestionado por Pacemaker, vinculándolo a la VIP con restricciones de orden y colocación. En general, el recurso gestionado por el clúster nunca debe ser iniciado/reiniciado por nada que no sea Pacemaker. Esto implica deshabilitar el servicio en systemd (
systemctl disable apache2) y dejar que Pacemaker controle su ciclo de vida. - Implementar STONITH: Configurar un dispositivo de fencing real (ej.
fence_xvmpara libvirt,fence_ipmilanpara IPMI) para ver cómo actúa el clúster al aislar automáticamente un nodo fallido. Comparar el comportamiento con y sin fencing. - Simular pérdida de red: Desconectar la interfaz de nodo-a (en vez de apagarlo) para observar cómo el clúster interpreta un nodo inaccesible. Luego reconectar y ver la reintegración.
- Pruebas de quorum en 3+ nodos: Si es posible, agregar un tercer nodo para observar cómo Pacemaker maneja el quórum con mayorías en vez del modo
two_node.
Tabla Resumen: Comando → Función → Verificación → Error Frecuente
| Paso | Comando(s) | Qué hace | Verificación | Error frecuente |
|---|---|---|---|---|
| 1 | hostnamectl set-hostname nodo-a/b | Establece el hostname del SO para que coincida con la config del clúster | hostname o uname -n muestra el nombre correcto | Hostname no coincide con la configuración del clúster |
| 1 | nano /etc/hosts (añadir entradas) | Habilita resolución de nombres entre nodos | ping nodo-b desde nodo-a (y viceversa) responde | Entrada incorrecta o duplicada en /etc/hosts |
| 1 | apt update && apt upgrade -y | Actualiza paquetes del sistema | Sin errores en la salida de apt | Repositorios mal configurados |
| 2 | apt install -y pacemaker corosync pcs | Instala el stack de HA completo | pcs --version muestra versión | Paquetes no encontrados en los repos |
| 2 | systemctl enable/start pcsd | Activa el demonio PCS para administración remota | systemctl status pcsd → active (running) | pcsd no arrancado → error de conexión en pasos posteriores |
| 3 | passwd hacluster (en ambos) | Asigna credenciales al usuario de gestión del clúster | Contraseña aceptada sin error | Contraseña distinta en cada nodo |
| 3 | pcs host auth nodo-a nodo-b | Establece confianza mutua entre nodos | «Authorized» para cada nodo | Hostname no resoluble o pcsd no activo |
| 4 | pcs cluster setup laboratorio-ha nodo-a nodo-b | Crea la configuración del clúster y la distribuye | Archivos de config distribuidos exitosamente | Auth no completada previamente |
| 4 | pcs cluster start --all | Inicia Corosync y Pacemaker en todos los nodos | pcs status → nodos Online | Firewall bloquea puertos UDP 5404/5405 |
| 4 | pcs cluster enable --all | Habilita arranque automático tras reboot | pcs status persiste tras reinicio | Olvidar este paso → clúster no arranca tras reboot |
| 5 | pcs property set stonith-enabled=false | Desactiva fencing (solo laboratorio) | pcs property list → stonith-enabled: false | No desactivar → recursos no inician |
| 5 | pcs resource create IP-Virtual ... | Crea recurso de IP flotante con agente IPaddr2 | pcs status → IP-Virtual: Started nodo-a | IP en subred incorrecta / IP duplicada en la red |
| 6 | ip addr | grep 192.168.1.100 | Confirma que la VIP está asignada en el nodo activo | Línea con inet 192.168.1.100/24 visible | IP no aparece → recurso no iniciado correctamente |
| 6 | ping 192.168.1.100 | Prueba de conectividad externa | Respuestas ICMP recibidas | Firewall bloquea ICMP o subred incorrecta |
| 7 | shutdown -h now (en nodo-a) | Simula fallo del nodo principal | En nodo-b: pcs status → IP-Virtual: Started nodo-b | Failover no ocurre → problema de quórum |
| 7 | ip addr | grep 192.168.1.100 (nodo-b) | Confirma migración de la VIP a nodo-b | VIP visible en interfaz de nodo-b | VIP no migró → revisar logs de Pacemaker |