DRBD (Dispositivo de Bloque Replicado Distribuido): Arquitectura y Funcionamiento Técnico
DRBD (Distributed Replicated Block Device) es una solución de almacenamiento replicado basada en software, de tipo shared-nothing, que refleja el contenido de dispositivos de bloque (discos duros, particiones, volúmenes lógicos, etc.) entre hosts. Funciona como un RAID-1 por red: replica datos en tiempo real de forma continua mientras las aplicaciones los modifican, de manera transparente (las aplicaciones no necesitan saber que los datos están en múltiples hosts), y de forma síncrona o asíncrona según la configuración elegida. Es una tecnología ampliamente utilizada para implementar alta disponibilidad (HA) en Linux: si un servidor falla, el otro posee una réplica actualizada de los datos para continuar operando. DRBD es software de código abierto, disponible en la plataforma Linux.
Dado que la imagen de referencia mencionada no está disponible para su análisis directo, la siguiente explicación describe la arquitectura típica que aparece en diagramas estándares de DRBD, explicitando las suposiciones realizadas.
1. Arquitectura por Capas de DRBD (Pila de I/O Linux)
DRBD es un módulo del kernel de Linux que se ubica entre el planificador de I/O (capa inferior) y el sistema de archivos (capa superior). Específicamente, constituye un controlador para un dispositivo de bloque virtual, posicionándose cerca de la parte inferior de la pila de I/O del sistema. La guía oficial de DRBD 9 hace referencia a esta disposición en su «Figura 1: Posición de DRBD dentro de la pila de I/O de Linux». [linuxparty.es][linbit.com]
La pila, de arriba hacia abajo, se organiza así:
- Aplicaciones del usuario (base de datos, servidor web, etc.) — generan operaciones de lectura/escritura sobre archivos.
- Sistema de archivos (EXT4, XFS, etc.) — traduce operaciones de archivo a operaciones de bloque sobre el dispositivo montado.
- DRBD (dispositivo virtual
/dev/drbdX) — intercepta cada operación de bloque y la replica al nodo remoto antes de (o simultáneamente a) pasarla al dispositivo local subyacente. El dispositivo DRBD tiene un número mayor (major number) de 147 y números menores a partir de 0.udevcrea además enlaces simbólicos por nombre de recurso para facilitar la administración. - Dispositivo de bloque local (partición, disco completo, RAID por software, LVM o EVMS) — el almacenamiento físico subyacente donde DRBD persiste los datos.
- Red TCP/IP — canal de comunicación con el nodo remoto (puertos TCP 7788 en adelante, por defecto) a través de una interfaz de red, idealmente dedicada para DRBD.
DRBD es, por definición y por mandato de la arquitectura del kernel de Linux, agnóstico de las capas superiores. No puede agregar mágicamente funcionalidades que las capas superiores no posean; por ejemplo, no puede auto-detectar corrupción del sistema de archivos ni agregar capacidad de clúster activo-activo a sistemas de archivos como ext3 o XFS que no la soportan nativamente.
Metadatos de DRBD: DRBD almacena metadatos internos en cada nodo. Cuando se usa la opción meta-disk internal (lo más habitual), estos metadatos se reservan en la parte final del dispositivo de bloque subyacente. Por ejemplo, si el dispositivo crudo tiene 1024 MB, el dispositivo DRBD dispondrá de solo 1023 MB para datos del usuario, con aproximadamente 70 KB reservados para metadatos. Es fundamental que toda manipulación de datos se haga sobre /dev/drbdX y no sobre el dispositivo crudo, ya que acceder al dispositivo directamente causará inconsistencias.
Herramientas de administración en espacio de usuario: DRBD incluye tres herramientas que se comunican con el módulo del kernel para configurar y administrar los recursos, de mayor a menor nivel:
| Herramienta | Nivel | Función |
|---|---|---|
drbdadm | Alto | Herramienta principal. Obtiene parámetros de /etc/drbd.conf y actúa como front-end para drbdsetup y drbdmeta. Soporta modo dry-run con la opción -d. |
drbdsetup | Bajo | Configura directamente el módulo DRBD cargado en el kernel. Todos los parámetros se pasan por línea de comandos. Rara vez se usa directamente. |
drbdmeta | Bajo | Permite crear, volcar, restaurar y modificar estructuras de metadatos DRBD. También de uso infrecuente para la mayoría de los usuarios. |
2. Topología Típica: Dos Nodos con Replicación por Red
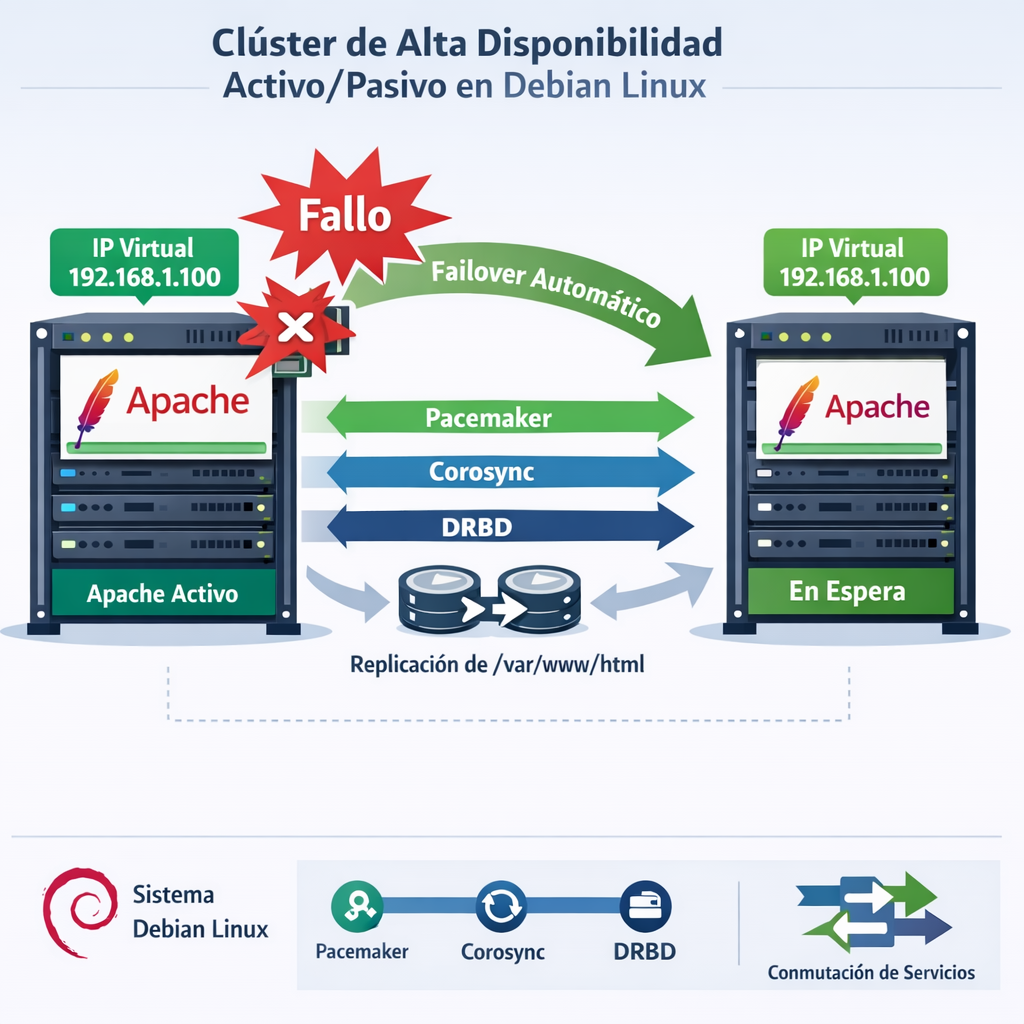
Los despliegues estándares de DRBD constan de dos servidores (Nodo A y Nodo B) conectados por red. Un diagrama de referencia típico (como la «Ilustración técnica y educativa» presente en los materiales de clase) muestra un clúster activo/pasivo en Linux con dos servidores: el Nodo A (activo) ejecutando Apache con una IP virtual (VIP) visible a los clientes, y el Nodo B (pasivo) en espera. Ambos nodos aparecen conectados por enlaces que representan Pacemaker, Corosync y DRBD, mostrando replicación en tiempo real del directorio /var/www/html. El diagrama ilustra además un evento de failover donde la IP virtual y el servicio Apache se mueven automáticamente del Nodo A al Nodo B cuando el Nodo A falla.
En esta disposición shared-nothing:
- El Nodo A (Primary) monta el volumen DRBD con un sistema de archivos convencional (p.ej., EXT4) y aloja el servicio activo.
- El Nodo B (Secondary) mantiene una copia espejo del volumen pero no lo monta mientras sea secundario; los datos están replicados a nivel de bloque pero no son accesibles como archivos hasta una eventual promoción.
- La replicación se realiza de forma continua a través de una interfaz de red dedicada para DRBD.
Tráfico de red no cifrado: La documentación oficial de SUSE advierte que el tráfico de datos entre espejos DRBD no está cifrado. Para un intercambio seguro de datos, se recomienda implementar una VPN sobre la conexión de replicación.
DRBD permite usar cualquier dispositivo de bloque soportado por Linux como almacenamiento subyacente: partición o disco duro completo, RAID por software, LVM o EVMS.
3. Flujo de I/O: Escrituras y Lecturas
Flujo de escritura (modo single-primary)
- Aplicación escribe: La aplicación emite una escritura sobre el dispositivo montado (
/dev/drbdX) en el nodo Primary. - DRBD intercepta y replica: Las escrituras al nodo primario se transfieren al dispositivo de bloque de nivel inferior y simultáneamente se propagan al nodo secundario. El secundario transfiere a su vez los datos a su propio dispositivo de bloque de nivel inferior.
- Confirmación (acknowledge): El momento de la confirmación a la aplicación depende del protocolo de replicación configurado (A, B o C), como se detalla en la siguiente sección.
Flujo de lectura
Toda la I/O de lectura se ejecuta localmente en el nodo primario, accediendo directamente al disco local sin añadir latencia de red, a menos que se configure balanceo de lectura (read-balancing), una opción avanzada donde el primario podría leer también desde el secundario vía red para distribuir carga. Esta opción no es habitual en configuraciones estándar. El nodo secundario no atiende lecturas porque no tiene aplicaciones activas ni un sistema de archivos montado.
Flujo en modo dual-primary
En configuración activo-activo, ambos nodos pueden originar escrituras; cada escritura local en un nodo se replica al otro. Las lecturas son atendidas localmente por cada nodo para sus propias aplicaciones. Un sistema de archivos de disco compartido (GFS2, OCFS2) junto con un gestor de bloqueos distribuido coordina la coherencia de acceso concurrente. Este modo de operación requiere latencias de red muy bajas y coordinación precisa.
4. Modos de Replicación: Protocolo A, B y C
DRBD soporta tres protocolos de replicación que representan tres grados distintos de sincronía. La elección influye en dos factores del despliegue: protección (de datos ante fallo) y latencia (percibida por la aplicación). El rendimiento (throughput), por el contrario, es en gran medida independiente del protocolo seleccionado.
Protocolo A — Replicación asíncrona
Las operaciones de escritura locales en el nodo primario se consideran completadas tan pronto como la escritura en disco local ha terminado y el paquete de replicación ha sido colocado en el buffer TCP de envío local. En caso de un failover forzado, puede ocurrir pérdida de datos: los datos en el nodo en espera son consistentes después del failover, pero las actualizaciones más recientes realizadas antes del failover podrían perderse. El Protocolo A se usa con mayor frecuencia en escenarios de replicación a larga distancia.
Protocolo B — Replicación semisíncrona («síncrono de memoria»)
También conocido como protocolo síncrono de memoria (memory-synchronous). En este modo, la escritura se confirma una vez que el disco local ha terminado y el nodo remoto ha acusado recibo de los datos (los ha recibido en su capa de red/memoria). No espera la persistencia en disco del secundario. Esto reduce la ventana de posible pérdida respecto al Protocolo A: si solo el Primario falla, el Secundario ya tiene los datos recibidos; sin embargo, si ambos nodos fallan simultáneamente antes de que el Secundario persista a disco, los datos podrían perderse.
Protocolo C — Replicación síncrona (completamente)
Es con diferencia, el protocolo de replicación más utilizado en configuraciones DRBD. La escritura se confirma solo después de que ambos nodos hayan persistido los datos en disco. Garantiza la máxima consistencia: ante un failover, ninguna actualización se pierde porque el secundario ya escribió todos los bloques confirmados. El costo es mayor latencia por escritura (incluye el retardo de red + I/O remoto). En redes LAN rápidas, este impacto es aceptable.
Tabla comparativa: Protocolo A vs B vs C
| Aspecto | Protocolo A (Asíncrono) | Protocolo B (Semisíncrono) | Protocolo C (Síncrono) |
|---|---|---|---|
| Confirmación de escritura | Tras disco local + paquete en buffer TCP | Tras disco local + recepción en memoria remota | Tras disco local + disco remoto |
| Latencia percibida | Mínima (similar a disco local solo) | Moderada (añade latencia de red, sin I/O remoto) | Mayor (red + I/O remoto por cada escritura) |
| Protección ante fallo del Primary | Posible pérdida de actualizaciones recientes | Datos normalmente seguros (en RAM remota); riesgo si ambos nodos fallan | Cero pérdida de datos en failover |
| Throughput | Independiente del protocolo | Independiente del protocolo | Independiente del protocolo |
| Uso típico | Réplica a larga distancia | Escenarios intermedios, sitios cercanos | Configuración más común en clústeres HA locales |
5. Roles, Estados y Monitorización
Roles: Primary y Secondary
Cada recurso DRBD tiene en cada momento un rol asignado en cada nodo. En modo single-primary, el recurso está en Primary en un solo miembro del clúster a la vez, garantizando que solo un nodo manipule los datos en cada momento. El Secundario recibe los bloques replicados pero típicamente no monta el sistema de archivos.
Estados observados en la práctica
El estado de un recurso DRBD se reporta mediante cat /proc/drbd (DRBD 8.4) o drbdadm status (DRBD 9, que ofrece una vista más legible)】. Un estado saludable se ve así:
cs:Connected ro:Primary/Secondary ds:UpToDate/UpToDate
Esto indica que ambos nodos están conectados, hay un nodo activo (Primary) y uno pasivo (Secondary), y los bloques de datos están idénticos (completamente sincronizados)【5000†L7-L10】.
Principales estados de conexión (cs), rol (ro) y disco (ds)
| Categoría | Estado | Significado |
|---|---|---|
| Conexión (cs) | Connected | Comunicación activa, replicación operativa en tiempo real【5000†L8-L9】 |
StandAlone / Disconnected | Sin conexión al par (fallo de red, split-brain detectado, etc.)【14†L11-L14】 | |
SyncSource | Este nodo está enviando bloques durante una sincronización activa【5000†L13】 | |
SyncTarget | Este nodo está recibiendo bloques durante una sincronización activa | |
| Rol (ro) | Primary/Secondary | Primer valor = rol local, segundo = rol del par【5000†L8-L9】 |
Primary/Primary | Ambos nodos en modo dual-primary (requiere FS compartido) | |
| Disco (ds) | UpToDate/UpToDate | Ambos discos completamente sincronizados (estado ideal)【5000†L9-L10】 |
UpToDate/Inconsistent | El primario está actualizado; el secundario aún no tiene todos los datos【5000†L13-L14】 | |
Diskless | No hay dispositivo de bloque local asignado al controlador DRBD (p.ej., el disco falló)【3†L16】 |
Sincronización en progreso
Cuando DRBD sincroniza datos por primera vez o tras una desconexión, el estado muestra información de progreso. Ejemplo de salida:
cs:SyncSource ro:Primary/Secondary ds:UpToDate/Inconsistent
sync'ed: 45.7% (46624/102400) finish: 0:01:12 speed: 12,000 K/sec
El porcentaje indica el avance de la copia de bloques hasta que ambos discos queden en estado UpToDate【5000†L13-L15】【5000†L57-L61】. Al terminar, la conexión vuelve a Connected normal.
6. Sincronización Inicial, Re-Sincronización y Recuperación
Sincronización inicial
Al configurar un recurso DRBD por primera vez, se debe designar un nodo como fuente de la sincronización inicial. Si un nodo ya contiene datos valiosos, se lo promueve a Primario inicial (por ejemplo con drbdadm primary --force) y DRBD copia todos los bloques al otro nodo hasta que ambos queden UpToDate【18†L1-L2】.
Si ambos nodos parten de discos nuevos e inicializados (sin datos valiosos), es posible omitir la sincronización inicial completa para ahorrar tiempo, usando un procedimiento especial que marca ambos nodos como sincronizados sin copiar bloques【2†L6-L7】.
Re-sincronización tras desconexión
Si la comunicación se pierde temporalmente o un nodo se reinicia, al reconectar DRBD sincroniza solo los bloques que fueron modificados durante la caída, no el dispositivo en su totalidad. Esto hace que la recuperación sea eficiente incluso para volúmenes grandes: un bitmap interno rastrea qué regiones cambiaron mientras los nodos estuvieron desconectados. DRBD elige automáticamente un nodo como SyncSource (normalmente el que estuvo activo) y el otro como SyncTarget, y el estado UpToDate/Inconsistent se muestra hasta completar el diferencial【5000†L11-L15】.
Recuperación de split-brain
Cuando un nodo víctima de split-brain se re-sincroniza con el nodo «ganador», no se realiza una sincronización completa del dispositivo. En su lugar, las modificaciones locales del nodo víctima se revierten, y las modificaciones realizadas en el nodo sobreviviente se propagan hacia el nodo víctima. Una vez completada la re-sincronización, el split-brain se considera resuelto y los nodos forman nuevamente un sistema de almacenamiento replicado totalmente consistente【14†L3-L5】.
7. Split-Brain: Detección, Prevención y Resolución
¿Qué es el split-brain?
Es una situación donde, debido a una falla temporal de todos los enlaces de red entre nodos del clúster, y posiblemente por intervención de software de gestión o error humano, ambos nodos cambian al rol Primary estando desconectados. Es un estado potencialmente dañino, pues implica que se pudieron realizar modificaciones en cualquiera de los nodos sin haberlas replicado al otro【14†L1】.
Detección
DRBD detecta el split-brain al momento en que la conectividad se restablece y los nodos intercambian el handshake inicial del protocolo DRBD. Si DRBD detecta que ambos nodos son (o fueron) Primary mientras estaban desconectados, corta inmediatamente la conexión de replicación. Los mensajes del log del sistema indicarán «Split-Brain detected»【14†L11-L14】.
Prevención: Fencing, STONITH y Quórum
La estrategia más efectiva es evitar el split-brain mediante:
- Fencing/STONITH: Configurar un recurso Shoot The Other Node In The Head en Pacemaker para que, si un nodo queda aislado, el clúster envíe un comando para apagarlo o reiniciarlo automáticamente, asegurando que solo quede uno activo escribiendo en DRBD.
- Quórum: DRBD 9 incorpora una funcionalidad de quorum que puede usarse como alternativa al fencing en clústeres Pacemaker, evitando el escenario de «split-brain» al requerir mayoría de nodos para permitir la promoción a Primary.
- Redundancia de comunicación: Múltiples enlaces de red entre nodos (heartbeat dedicado + red de replicación) reducen la probabilidad de aislamiento total.
La documentación oficial advierte que configurar DRBD para resolver automáticamente divergencias de datos causadas por split-brain es configurar para potencial pérdida automática de datos, y recomienda considerar las implicaciones antes de habilitarlo. Lo preferible es invertir en políticas de fencing, configuración de quórum, integración con gestor de clúster y enlaces de comunicación redundantes para evitar la divergencia de datos【14†L7-L9】.
Resolución: Políticas after-sb
Si pese a todo ocurre un split-brain, DRBD ofrece opciones configurables de resolución automática (políticas after-sb-0pri, after-sb-1pri, after-sb-2pri):
discard-zero-changes: Descarta los cambios del nodo que no realizó ninguna modificación (si aplica)【14†L19】.discard-secondary: Descarta siempre los cambios del nodo actualmente en rol Secundario cuando se detecta el split-brain【14†L9-L10】.discard-younger-primary/discard-older-primary: Descarta las modificaciones del nodo que fue promovido a Primary más recientemente o más antiguamente, respectivamente【14†L21-L23】.disconnect: Simplemente corta la conexión y continúa en modo desconectado, dejando la resolución al administrador【14†L9-L10】.
Todas estas políticas conllevan potencial pérdida de datos, ya que una de las copias divergentes será revertida. En entornos donde no es aceptable descartar datos automáticamente (p.ej., bases de datos financieras), se recomienda no habilitar recuperación automática y requerir intervención manual en todo evento de split-brain【14†L21-L25】.
Un ejemplo de configuración de políticas para un recurso con sistema de archivos GFS u OCFS2 en modo dual-primary:
resource <nombre> {
handlers {
split-brain "/usr/lib/drbd/notify-split-brain.sh root"
}
net {
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
}
}
【14†L19】
Split-brain y dual-primary
En modo dual-primary, dado que ambos recursos están siempre como primarios, cualquier interrupción en la red entre nodos resultará en un split-brain. En DRBD 9.0.x, el modo Dual-Primary está limitado a exactamente dos Primarios y su uso previsto es la migración en vivo de máquinas virtuales【23†L15-L16】. Para habilitar este modo de forma permanente, se configura la opción allow-two-primaries a yes en la sección net del archivo de configuración del recurso【23†L15-L16】.
8. Integración con Pacemaker, Corosync y Orden de Recursos
DRBD proporciona la replicación de datos, pero no gestiona la conmutación de servicios ni la supervisión de nodos. En un entorno de alta disponibilidad real, se integra con Pacemaker (gestor de recursos de clúster) usando Corosync como capa de comunicación. La guía oficial de DRBD 9 cubre explícitamente la integración con Pacemaker, además de configuraciones avanzadas con LVM, GFS, OCFS2 y el software DRBD Reactor desarrollado por LINBIT como alternativa más sencilla de configurar y desplegar【1†L21】.
Arquitectura de recursos en Pacemaker
Según los materiales de configuración para alta disponibilidad con DRBD y Pacemaker, el orden correcto de arranque de recursos siempre debe ser:
DRBD → Filesystem → Apache → IP Virtual
Pacemaker se encarga de orquestar todo este flujo【5000†L82-L83】.
Los pasos clave de configuración incluyen:
- Recurso DRBD en Pacemaker: Controla quién es Primary y quién es Secondary. Ejemplo:
pcs resource create drbd-webdata ocf:linbit:drbd drbd_resource=webdata op monitor interval=30s【5000†L89-L91】. - Recurso Filesystem: Monta
/dev/drbd0en el directorio de datos solo en el nodo activo. Ejemplo:pcs resource create fs-webdata ocf:heartbeat:Filesystem device="/dev/drbd0" directory="/var/www/html" fstype="ext4"【5000†L93-L95】. - Restricción de orden (order constraint): Primero DRBD debe estar promovido, luego se monta el filesystem:
pcs constraint order promote drbd-webdata then start fs-webdata【5000†L97-L98】. - Restricción de colocación (colocation constraint): Evita que se monte en un nodo Secondary:
pcs constraint colocation add fs-webdata with drbd-webdata INFINITY【5000†L100-L101】.
Flujo de failover automático
En condiciones normales, todos los recursos corren en el Nodo A. Si Pacemaker detecta que el Nodo A falla (no responde al heartbeat de Corosync o un recurso falla), automáticamente:
- Promueve el Nodo B a Primary de DRBD.
- Monta el sistema de archivos en el Nodo B.
- Arranca la aplicación (Apache, etc.) en el Nodo B.
- Mueve la IP virtual al Nodo B.
Todo ello respetando el orden secuencial definido【5000†L78-L83】. Si STONITH está configurado, antes de promocionar al Nodo B se envía una señal para apagar el Nodo A y asegurar que no pueda retomar la actividad con datos obsoletos.
Precondiciones críticas para el failover
Para que el failover funcione correctamente, se deben cumplir estas precondiciones【5000†L85-L88】:
- ✅ DRBD ya está sincronizado →
UpToDate/UpToDate - ✅ El directorio de datos (
/var/www/html) no está montado manualmente - ✅ El servicio (Apache) está detenido (lo controla Pacemaker)
- ✅ El clúster PCS ya está creado y activo
Verificación mediante: pcs status y drbdadm status【5000†L87-L88】.
9. Tabla Comparativa: Single-Primary vs Dual-Primary
| Aspecto | Single-Primary (Activo/Pasivo) | Dual-Primary (Activo/Activo) |
|---|---|---|
| Nodos con acceso R/W | Solo uno a la vez【4†L13】 | Ambos simultáneamente【23†L15-L16】 |
| Sistema de archivos requerido | Convencional (EXT4, XFS, etc.)【1†L45】 | Distribuido de disco compartido (GFS2, OCFS2) con gestor de bloqueos |
| Riesgo de split-brain | Menor (solo si el gestor de clúster falla en la coordinación) | Toda interrupción de red resulta en split-brain【23†L15-L16】 |
| Complejidad | Menor; configuración estándar más común | Mayor; requiere lock manager y FS especial |
| Caso de uso típico | HA para bases de datos, servidores web, NFS | Migración en vivo de VMs, balanceo de carga con escritura concurrente |
| Limitación en DRBD 9.0.x | Sin limitación especial | Limitado a exactamente 2 Primarios【23†L15-L16】 |
10. Apilamiento (Stacking) y Replicación de Tres Vías
Para escenarios de backup y recuperación ante desastres, DRBD soporta replicación de tres vías mediante la técnica de stacking: se agrega otro recurso DRBD apilado sobre el recurso existente que contiene los datos de producción. El recurso apilado se replica usando replicación asíncrona (Protocolo A), mientras que los datos de producción típicamente usan replicación síncrona (Protocolo C)【23†L25】. Esto permite tener, por ejemplo, dos nodos locales con replicación síncrona (máxima protección) y un tercer nodo remoto recibiendo una copia asíncrona para disaster recovery.
11. Casos de Uso y Limitaciones Arquitectónicas
Casos de uso típicos
DRBD opera dentro de la capa de bloques del kernel de Linux, por lo que es agnóstico de la carga de trabajo. Puede servir como base de【1†L43-L45】:
- Servidores de archivos y web: Replicar volúmenes de datos (como
/var/www/html) para lograr failover sin pérdida de datos. También volúmenes NFS en modo activo-pasivo. - Bases de datos relacionales: MySQL/MariaDB, PostgreSQL u otras bases montadas sobre DRBD en un nodo primario. En un failover, el secundario asume con la base de datos consistente (tras journal replay si el primario cayó de forma no limpia).
- Entornos de virtualización: DRBD sirve de almacenamiento compartido para hipervisores (KVM, Xen) sin necesidad de SAN. Permite migración en vivo en dual-primary o failover en single-primary.
- Almacenamiento general HA: Cualquier aplicación que requiera acceso directo a un dispositivo de bloque.
- LINSTOR: Desde 2018, DRBD puede también aprovecharse en el software de gestión de almacenamiento de bloques LINSTOR para replicación entre nodos y provisión de dispositivos de bloque a usuarios y aplicaciones.
Verificación práctica de la replicación (contexto docente)
Una forma didáctica de comprobar la sincronización es crear un archivo en el nodo activo (Primary): echo "Hola DRBD" > /var/www/html/prueba.txt. Aunque el archivo no es visible en el nodo Secondary (porque no tiene montado el sistema de archivos), los datos ya se encuentran replicados a nivel de bloque. Al realizar un failover manual y montar DRBD en el nodo pasivo, el archivo creado aparece inmediatamente, confirmando que la replicación fue exitosa【5000†L20-L26】. DRBD replica bloques de disco, no archivos【5000†L26-L27】.
Limitaciones y consideraciones
- Duplicación de hardware: DRBD requiere almacenamiento de tamaño similar en cada nodo. No ahorra espacio; a cambio brinda redundancia contra la falla de un servidor completo. No protege contra errores lógicos: si una aplicación borra datos en el primario, esa eliminación se replica inmediatamente. Se complementa con copias de seguridad tradicionales.
- Impacto en latencia de escritura: Aunque las lecturas son locales, las escrituras incluyen la sobrecarga de replicación por red. En Protocolo C, la latencia de cada escritura incluye el retardo de red más el I/O del segundo nodo. En una LAN rápida el impacto es aceptable, pero en enlaces lentos puede ser significativo. El Protocolo A reduce este impacto a costa de menor seguridad de datos.
- No sustituye a un Cluster Filesystem: En modo single-primary, intentar montar un sistema de archivos convencional (EXT4, XFS) en ambos nodos simultáneamente corrompería los datos, ya que estos FS no están diseñados para acceso concurrente multi-nodo. Para escritura paralela se requiere GFS2, OCFS2 u otro FS distribuido. DRBD no puede agregar capacidad activo-activo a sistemas de archivos que no la poseen nativamente【1†L45】.
- Escalabilidad limitada en configuración clásica: DRBD está pensado principalmente para 2 nodos. La versión 9 amplió soporte a múltiples secundarios, pero para topologías más complejas de almacenamiento replicado a gran escala se consideran alternativas como Ceph o GlusterFS. DRBD destaca cuando 2 nodos bastan para HA y se desea aprovechar sistemas de archivos tradicionales con la simplicidad de un RAID-1 en red.
- Enlaces de red confiables: Dado que DRBD no cifra ni comprime datos en tránsito por defecto【7†L30-L32】, se asume una red local segura o el uso de VPN si el medio es inseguro. La estabilidad de la latencia de red también es importante; variaciones grandes afectan el rendimiento perceptiblemente, especialmente en Protocolo C.
- Reserva de metadatos: Cuando se usa
meta-disk internal, DRBD consume una pequeña porción del dispositivo para sus metadatos (~70 KB en un dispositivo de 1024 MB)【7†L65】, reduciendo ligeramente el espacio disponible para datos de usuario.【5000†L16-L18
Practicas:
Práctica: Clúster de Alta Disponibilidad en Debian 13
Practica: Integración de Apache2 en el Clúster de Alta Disponibilidad (Pacemaker + Corosync)
Práctica: DRBD en Debian 13.4: Replicación de Volumen Paso a Paso
MySQL en Debian 13.4 — Clúster de Alta Disponibilidad con DRBD y Replicación Nativa