MySQL en Debian 13.4 — Clúster de Alta Disponibilidad con DRBD y Replicación Nativa
Objetivos del Laboratorio Objetivo general: Implementar un clúster de alta disponibilidad de MySQL 8.0 en Debian 13.4 utilizando DRBD para replicación de almacenamiento a nivel de bloque y configurando simultáneamente la replicación nativa de MySQL (Primary‑Replica). El entorno final constará de dos nodos (nodo‑a y nodo‑b) capaces de garantizar continuidad del servicio de base de datos, replicación síncrona de almacenamiento y sincronización a nivel de transacciones SQL. Objetivos específicos: # Objetivo Alcance 1 Comprender qué es MySQL Definición, características clave, modelo relacional 2 Identificar la estructura de archivos de MySQL datadir, InnoDB, logs, socket, configuración 3 Instalar MySQL 8.0 en Debian 13.4 Repositorio oficial Oracle, configuración segura 4 Integrar MySQL en clúster HA DRBD + Pacemaker/Corosync, datadir sobre volumen replicado 5 Configurar replicación nativa MySQL Primary‑Replica, usuario de replicación, binlog, verificación 6 Validar y documentar pruebas Failover, integridad de datos, problemas comunes Nota sobre las referencias del laboratorio previo: Las prácticas publicadas en dsantana.uas.edu.mx —sobre implementación de clúster HA, DRBD en Debian 13.4 y clúster de alta disponibilidad en Debian 13— no pudieron consultarse directamente durante la investigación. La presente guía se construye sobre documentación oficial de MySQL (Oracle), guías técnicas verificadas de instalación en Debian, y referencias de configuración de Pacemaker/Corosync/DRBD, alineándose con los principios y arquitectura descritos en dichas prácticas previas. 1. ¿Qué es MySQL? MySQL es un sistema de gestión de bases de datos relacionales (RDBMS) de código abierto que se utiliza para almacenar y gestionar datos. Su fiabilidad, rendimiento, escalabilidad y facilidad de uso lo han convertido en una opción popular para desarrolladores en aplicaciones de alto tráfico como Facebook, Netflix, Uber, Airbnb, Shopify y Booking.com. En 2024, MySQL se clasifica como la segunda base de datos más popular en general, solo superada por Oracle Database según DB‑Engines, y es el RDBMS de código abierto más popular del mundo. MySQL utiliza el lenguaje SQL (Structured Query Language) para recuperar, actualizar, suprimir y manipular datos en bases de datos relacionales. Se pronuncia oficialmente «My es‑kiu‑el». Como base de datos relacional, almacena datos en tablas de filas y columnas organizadas en esquemas, donde un esquema define cómo se organizan y almacenan los datos y describe la relación entre varias tablas. Recientemente, Oracle ha añadido soporte para el tipo de datos JSON y vectores, ampliando su versatilidad. Características fundamentales: 2. Estructura del Sistema de Archivos y Componentes de MySQL 2.1 Directorio de datos (datadir) El datadir es la carpeta principal donde el servidor MySQL almacena todos los archivos relacionados con las bases de datos. En instalaciones desde repositorios (apt, yum) en Linux, la ubicación más común es /var/lib/mysql/. Este valor está definido por la variable del sistema data_dir, cuyo valor por defecto es /var/lib/mysql. Para consultar el datadir activo, puede ejecutarse dentro de MySQL la sentencia SHOW VARIABLES LIKE ‘datadir’;. Dentro del datadir se encuentra: 2.2 Motor de almacenamiento InnoDB InnoDB es el motor de almacenamiento predeterminado en MySQL 8.0 y actúa como la capa intermedia entre el almacenamiento y el servidor MySQL, almacenando los datos en las unidades de disco. Su funcionamiento de E/S se clasifica en dos tipos: I/O de archivo aleatorio (archivos de datos) y E/S de archivo secuencial (registros de recuperación y binarios). Componentes clave de InnoDB en el datadir: Componente Descripción Espacio de tablas compartido (ibdata1) Contiene metadatos de InnoDB y datos de tablas que no usan file‑per‑table. Con innodb_file_per_table activado (predeterminado en MySQL 8), cada tabla se almacena en archivos .ibd independientes. Logs de recuperación (redo logs) Registros transaccionales escritos secuencialmente para garantizar la recuperación tras fallos. Buffer de doble escritura InnoDB escribe páginas primero en un buffer y luego en sus posiciones correctas en los archivos de datos, evitando la corrupción de páginas si se produce un fallo de alimentación durante la escritura. Buffer de inserción Reduce operaciones de E/S aleatorias fusionando escrituras en índices secundarios no únicos. Segmentos de deshacer (undo) Registran imágenes anteriores de los datos para la concurrencia multiversión (MVCC). 2.3 Archivos de registro (logs) MySQL dispone de cuatro tipos principales de archivos de log: Tipo de log Descripción Ruta típica (Debian) Activado por defecto Registro de errores Registra problemas al iniciar, ejecutar o parar mysqld /var/log/mysql/error.log Sí Registro de consultas generales Registra todas las conexiones y sentencias ejecutadas datadir/<hostname>.log No Registro binario (binlog) Registra todas las sentencias que cambian datos; utilizado en la replicación datadir/mysql-bin.* (si se activa log_bin) No Registro de consultas lentas Registra sentencias que exceden el tiempo definido por long_query_time (predeterminado: 10 segundos) datadir/<hostname>-slow.log No Por defecto, todos los archivos de log se crean en el directorio de datos, aunque distribuciones Debian/Ubuntu suelen redirigir el log de errores a /var/log/mysql/error.log mediante la variable log_error. El registro binario merece atención especial para este laboratorio: es la base de la replicación nativa de MySQL. Debe habilitarse configurando log_bin en el archivo de configuración. Cada archivo binlog se escribe secuencialmente y contiene las operaciones de escritura (INSERT, UPDATE, DELETE). Los binlogs cumplen tres funciones principales: restauración punto en el tiempo, replicación entre servidores, y auditoría de seguridad. 2.4 Archivo de socket Unix El archivo mysqld.sock es un punto final de comunicación que permite que el servidor MySQL y las aplicaciones cliente en la misma máquina se comuniquen de manera local sin pasar por la red TCP/IP. En sistemas Debian/Ubuntu, este socket se encuentra normalmente en /var/run/mysqld/mysqld.sock. Se configura mediante la directiva socket en el archivo my.cnf. 2.5 Archivo PID y archivo de configuración 2.6 Parámetros de configuración relevantes Los parámetros de MySQL se dividen en dinámicos (modificables en tiempo de ejecución con SET) y estáticos (requieren reinicio del servicio). Algunos parámetros clave: Parámetro Tipo Descripción innodb_buffer_pool_size Estático Tamaño del buffer de datos/índices InnoDB en memoria log_bin Estático Activa registro binario para replicación server_id Estático Identificador único del servidor en topología de replicación bind-address Estático Dirección IP en la que MySQL escucha conexiones sync_binlog Dinámico Frecuencia de sincronización del binlog al disco; 1 = máxima seguridad 2.7 Permisos y AppArmor MySQL ejecuta bajo el usuario del sistema mysql. Todos los archivos del datadir deben pertenecer a mysql:mysql. En
Práctica: Clúster de Alta Disponibilidad en Debian 13
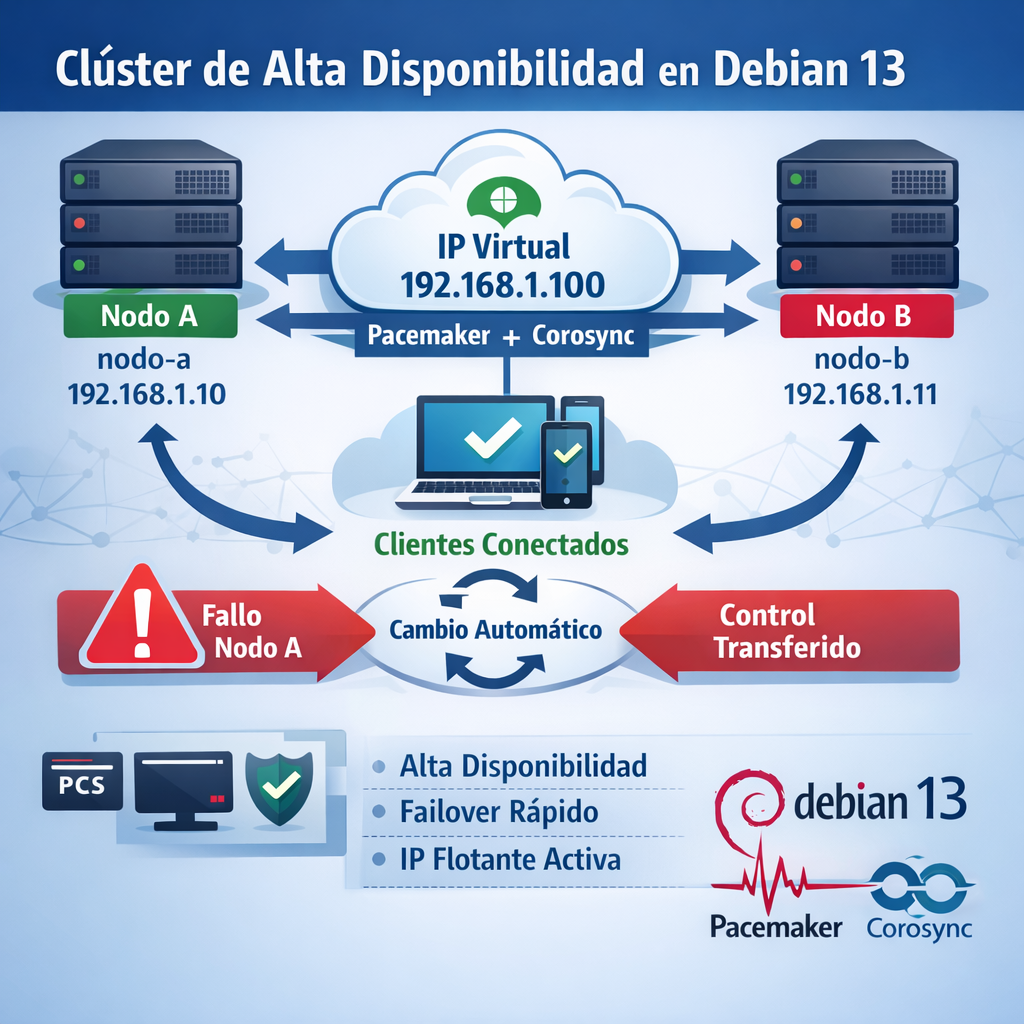
Descripción general: En esta práctica crearemos un clúster de alta disponibilidad (HA) de dos nodos en modo activo/pasivo usando Pacemaker (gestor de recursos de clúster) y Corosync (servicio de comunicación entre nodos) sobre Debian 13. El objetivo es que un recurso (una dirección IP virtual) esté siempre disponible: si el Nodo A falla, el Nodo B tomará automáticamente el control, minimizando la interrupción del servicio (failover). Configuraremos la IP virtual 192.168.1.100 que «flotará» entre los nodos, de modo que los clientes se conecten siempre a esa dirección sin importar qué servidor físico la esté atendiendo. Se trata de configurar un clúster de alta disponibilidad activo/pasivo en el que uno de los dos equipos pueda responder siempre a la dirección IP que se pretende mantener en alta disponibilidad. Escenario del laboratorio: Elemento Nodo A Nodo B Hostname nodo-a nodo-b IP fija 192.168.1.10 192.168.1.11 IP virtual (VIP) 192.168.1.100 (la asume cuando A falla) SO Debian 13 mínimo Debian 13 mínimo Conceptos clave: Antes de empezar, repasemos los términos esenciales que se usan a lo largo de la práctica: A continuación se detalla paso a paso la configuración, explicando qué hace cada comando, por qué es necesario y qué ocurre internamente en el clúster. Cada paso incluye verificaciones, posibles errores comunes y cómo identificarlos. Al final se proponen preguntas de análisis y criterios de evaluación. Paso 1: Preparación de los Nodos (hostname, /etc/hosts, actualización) Qué se hace: En cada servidor asignamos nombres de host descriptivos, aseguramos la resolución de nombres entre ellos y actualizamos el sistema operativo. 1.1 Cambiar el hostname En Nodo A: hostnamectl set-hostname nodo-a En Nodo B: hostnamectl set-hostname nodo-b Esto define el nombre de máquina a nivel del sistema (reflejado en uname -n y hostname). Los nombres de host deben coincidir exactamente con los que usaremos en la configuración del clúster. Pacemaker y Corosync no usan el prompt de la terminal ni apodos; identifican los nodos por su hostname real del SO. Si hay discrepancia (por ejemplo, el hostname del sistema es debian-01 pero en la configuración del clúster se escribe nodo-a), el clúster no reconocerá correctamente a los nodos, provocando errores de autenticación y conectividad. En un entorno de clúster, para cambiar el nombre de una máquina se puede ejecutar hostnamectl set-hostname nombre_nuevo. [blogsaverr…dalucia.es] 1.2 Editar /etc/hosts En ambos nodos, abrir /etc/hosts: nano /etc/hosts Y añadir las siguientes entradas: De esta manera, cada nodo puede resolver el nombre del otro por IP. Esto es fundamental porque pcs y Corosync utilizarán los nombres (nodo-a, nodo-b) para establecer la comunicación. Sin resolución correcta, los comandos de autenticación o arranque de clúster fallarán al no poder encontrar el host destino. El blog de maquinasvirtuales.eu muestra un ejemplo de /etc/hosts configurado para un clúster Pacemaker, donde cada nodo tiene su IP y nombre mapeados correctamente. 1.3 Actualizar el sistema En ambos nodos: apt update && apt upgrade -y Mantener Debian actualizado garantiza versiones compatibles de Pacemaker, Corosync y PCS. Tras una actualización que incluya kernel nuevo, es recomendable reiniciar los nodos antes de continuar. Verificación: Errores comunes: Problema Síntoma / Mensaje Solución Hostname no cambiado pcs indica «no configuration for host X» o el nombre no aparece en pcs status. Verificar con uname -n. Si no coincide, reejecutar hostnamectl set-hostname y reiniciar la sesión. Resolución de nombres fallida pcs host auth se cuelga o muestra error de conexión/refused hacia nodo-b. Verificar las entradas en /etc/hosts de ambos nodos. Probar ping nodo-b desde nodo-a. Firewall bloquea puertos de clúster Un nodo aparece OFFLINE en pcs status tras configurar el clúster. Asegurar que el firewall permite tráfico UDP 5404/5405 (puertos estándar de Corosync). En laboratorio, ufw disable o abrir reglas específicas. Paso 2: Instalación del Stack de Clúster (Pacemaker, Corosync, PCS) Qué se hace: Se instalan en ambos nodos los tres componentes del stack de HA: apt install -y pacemaker corosync pcs Este comando instala: [linuxmind.dev] Tras la instalación, habilitamos y arrancamos PCSD en cada nodo: systemctl enable pcsd systemctl start pcsd pcsd escucha en cada nodo y permite que, al autenticarse, podamos ejecutar comandos de configuración del clúster en todos los nodos desde uno solo. Por qué se hace: Pacemaker y Corosync forman el motor del clúster HA. Sin Pacemaker no habría orquestación de recursos; sin Corosync no habría detección de fallos entre nodos. La herramienta pcs simplifica enormemente la configuración, evitando la edición manual de archivos XML o configuración de Corosync; además, distribuye automáticamente las claves de autenticación a todos los nodos. Habilitar pcsd lo hace persistente tras reinicios. Internamente: Componentes internos de Pacemaker que conviene conocer: Verificación: Errores comunes: Problema Síntoma / Mensaje Solución Repositorios faltantes apt no encuentra paquetes pacemaker o pcs. Asegurarse de tener los repositorios de Debian 13 correctos en /etc/apt/sources.list. Permisos insuficientes Error de permisos al instalar. Ejecutar como root o con sudo. pcsd no habilitado Al intentar autenticación, pcs responde «Error: unable to connect to node…». Verificar que pcsd está activo en ambos nodos (systemctl status pcsd). Iniciar/habilitar si es necesario. Versiones distintas entre nodos Errores de protocolo o incompatibilidad durante la autenticación. Usar la misma versión de paquetes en ambos nodos (mismo SO y actualizaciones). Paso 3: Autenticación del Clúster (usuario hacluster y pcs host auth) Qué se hace: Para que pcs pueda controlar ambos nodos de forma remota, se usa un usuario dedicado llamado hacluster (creado automáticamente al instalar pcs). Se realizan dos tareas: 3.1 Asignar contraseña al usuario hacluster En cada nodo (ambos): passwd hacluster Elegir una contraseña (se recomienda la misma en ambos para simplificar el proceso de autenticación). Este usuario es el que pcs utiliza internamente para autenticarse contra los nodos del clúster. 3.2 Autenticación entre nodos Desde nodo-a: pcs host auth nodo-a nodo-b Este comando establece la confianza mutua entre nodo-a y nodo-b. pcs solicita las credenciales del usuario hacluster y las usa para crear una relación de confianza segura entre ambos nodos. Si pide confirmación de huella digital (fingerprint), aceptar con «yes». Por qué se hace: Sin autenticación, pcs solo puede administrar el nodo local. Este paso habilita
Práctica DRBD en Debian 13.4: Replicación de Volumen Paso a Paso

Contexto: Esta práctica configura DRBD (Distributed Replicated Block Device) en dos nodos (denominados nodo-a y nodo-b) con Debian 13.4, para replicar un volumen de datos entre ambos en tiempo real. Cada nodo cuenta con una partición adicional (p.ej. /dev/sdb1) de tamaño idéntico destinada a DRBD. El objetivo es lograr un «RAID-1 de red»: cualquier cambio en el nodo Primario se replicará al Secundario de forma continua, manteniendo ambas copias sincronizadas. DRBD es un módulo del kernel de Linux que se ubica entre el planificador de I/O (parte inferior) y el sistema de archivos (parte superior), actuando como controlador de un dispositivo de bloque virtual. Esto significa que las aplicaciones leen y escriben datos sin saber que, en la capa de bloques, esos datos están siendo duplicados por red en otro servidor — la replicación es transparente para ellas. A continuación se explica cada paso en detalle, indicando qué se hace, por qué se hace y qué ocurre internamente en la pila de I/O de Linux (aplicación → sistema de archivos → dispositivo DRBD → disco → red), junto con verificaciones, advertencias y errores comunes. Paso 1: Instalación de DRBD en ambos nodos Qué se hace: Se instala el paquete de utilidades de DRBD en los dos servidores. En Debian, el paquete se denomina drbd-utils y contiene las herramientas de espacio de usuario (drbdadm, drbdsetup, drbdmeta) necesarias para configurar y manejar DRBD. En Debian, la porción de módulo de DRBD se distribuye con los kernels de Debian, por lo que instalar drbd-utils generalmente es suficiente sin compilar nada adicional. El comando es: Esto se ejecuta en nodo-a y nodo-b. La opción -y auto-confirma la instalación. Se instalan las herramientas de administración que se comunican con el módulo del kernel para configurar y administrar los recursos DRBD. Por qué se hace: DRBD tiene dos componentes: un módulo en el kernel (el driver de bloque replicado, con número mayor de dispositivo 147) y herramientas en user-space para su administración. Sin instalar drbd-utils, no tendríamos los comandos necesarios para crear metadatos, levantar recursos ni monitorear el estado de la replicación. Internamente (capa afectada): Aquí solo añadimos software; aún no cambia nada en la pila de I/O. Tras la instalación, el módulo kernel estará disponible para cargarse al usarlo más adelante, y las herramientas de administración quedarán listas. Verificación: Errores comunes: Problema Síntoma Solución Repositorios o red apt falla al descargar paquetes Verificar conexión a internet y que /etc/apt/sources.list tenga repositorios válidos Permisos insuficientes Error de permisos al instalar Ejecutar como root o con sudo Módulo kernel ausente (entorno virtual) modprobe drbd falla con «Module not found» En kernels virtuales, instalar linux-modules-extra-$(uname -r) Versiones distintas entre nodos Error de protocolo al conectar nodos Asegurar que ambos nodos tengan la misma versión de drbd-utils Paso 2: Preparación del disco o partición en cada nodo Qué se hace: Se designa un dispositivo de bloque dedicado en cada servidor para la replicación. En producción se suele usar un disco entero; en laboratorio, una partición (p.ej. /dev/sdb1). Es fundamental que esta partición: (a) tenga el mismo tamaño en ambos nodos, y (b)no esté montada ni en /etc/fstab. La verificación se realiza con: Este comando lista los dispositivos de bloque. Debe confirmarse que /dev/sdb1 existe en ambos nodos, que no tenga punto de montaje asignado y que su tamaño sea idéntico. Por qué se hace: DRBD replica bloques de datos crudos. Necesitamos almacenamiento dedicado que DRBD controlará exclusivamente. Ambas particiones deben ser de tamaño idéntico para que la réplica funcione correctamente. DRBD soporta cualquier dispositivo de bloque soportado por Linux: partición o disco duro completo, RAID por software, LVM o EVMS. Internamente (capa afectada): Solo preparamos la capa de almacenamiento físico (el nivel más bajo de la pila I/O). No hemos configurado DRBD ni hay tráfico de red aún. Verificación: Errores comunes: Problema Síntoma Solución Partición montada drbdadm create-md falla al bloquear dispositivo Desmontar con umount y verificar que ningún proceso la use (lsof /dev/sdb1) Tamaño inconsistente DRBD ajusta al menor, dejando espacio desperdiciado Reparticionar al mismo tamaño antes de continuar Confundir disco y partición Apuntar a /dev/sdb cuando debe ser /dev/sdb1 Verificar con lsblk y usar exactamente la ruta que aparece en la configuración Datos previos en la partición Advertencia de destrucción de datos al inicializar Si los datos no son necesarios, confirmar; si lo son, respaldarlos primero Paso 3: Configuración básica del recurso DRBD (/etc/drbd.d/web.res) Qué se hace: Se crea un archivo de configuración que define el recurso DRBD (el nombre lógico de la pareja de discos replicados). El archivo /etc/drbd.d/web.res debe ser idéntico en ambos nodosy contiene: Explicación línea por línea Comparativa rápida de protocolos: Protocolo Tipo Confirmación de escritura Riesgo ante fallo del Primary A (Asíncrono) Tras disco local + paquete en buffer TCP Posible pérdida de las actualizaciones más recientes B (Semisíncrono) Tras disco local + recepción en memoria remota Datos normalmente seguros; riesgo si ambos nodos fallan simultáneamente C (Síncrono) ✅ Tras disco local + disco remoto Cero pérdida de datos Por qué se hace: Esta configuración define cómo se conectará y comportará el recurso replicado: qué disco local usar, a qué compañero conectarse por red, con qué garantías de sincronización y dónde guardar los metadatos internos. Internamente (capa afectada): Solo se modifica la capa de configuración (espacio de usuario). Todavía no se han creado dispositivos ni comunicaciones de red. Estamos preparando la «hoja de ruta» que DRBD seguirá. Verificación: Errores comunes / Advertencias: Problema Síntoma Solución Error de sintaxis en .res drbdadm indica número de línea con error Revisar corchetes, puntos y coma, y ortografía Nombre de host incorrecto «No valid configuration found for this host» uname -n debe coincidir con la sección on <nombre> en el archivo Archivo no copiado al segundo nodo Segundo nodo queda en StandAlone, no reconoce recurso Copiar con scp el archivo .res al otro nodo Puerto bloqueado por firewall Los nodos no conectan (cs:Timeout) Abrir el puerto TCP configurado en ambos nodos Paso 4: Inicializar el recurso DRBD en ambos nodos (metadatos y arranque) Se ejecutan
Implementación de un Clúster de Alta Disponibilidad con Replicación de Datos en Tiempo Real
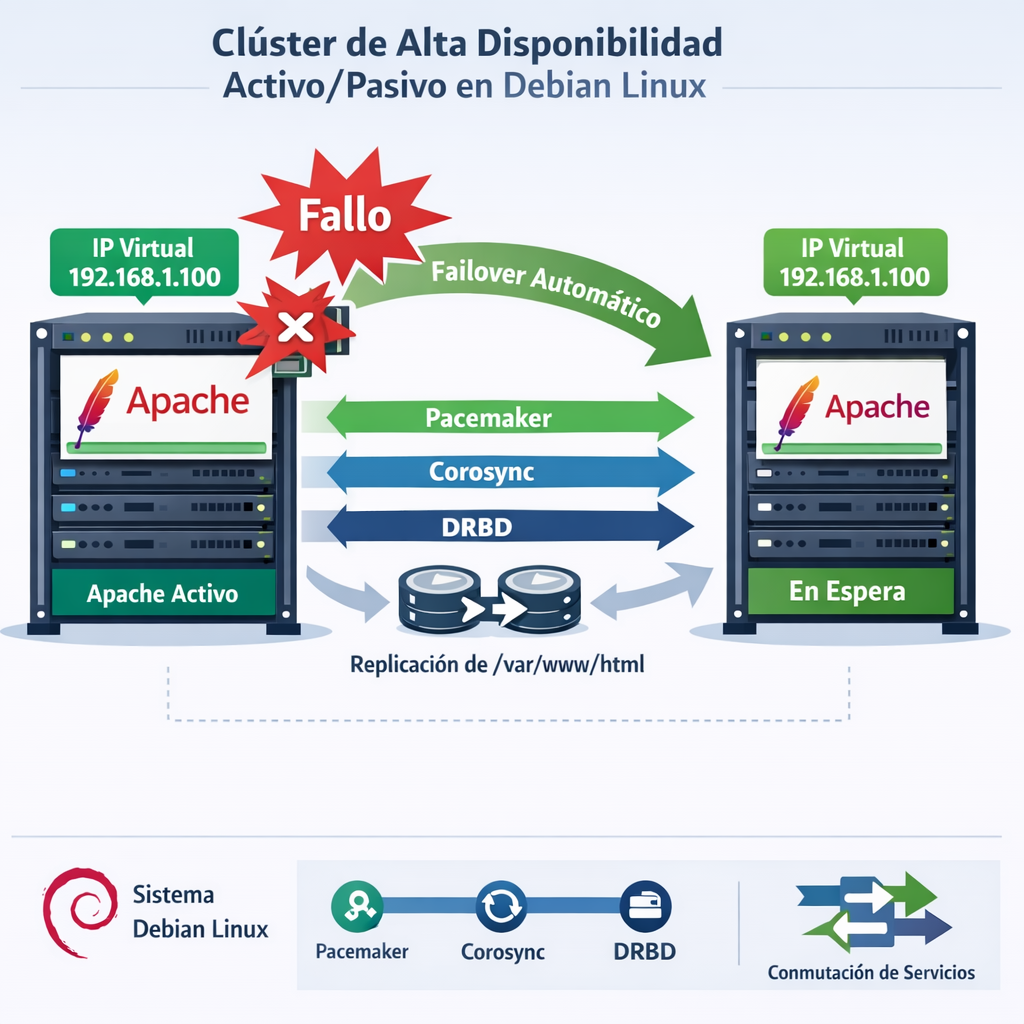
DRBD (Dispositivo de Bloque Replicado Distribuido): Arquitectura y Funcionamiento Técnico DRBD (Distributed Replicated Block Device) es una solución de almacenamiento replicado basada en software, de tipo shared-nothing, que refleja el contenido de dispositivos de bloque (discos duros, particiones, volúmenes lógicos, etc.) entre hosts. Funciona como un RAID-1 por red: replica datos en tiempo real de forma continua mientras las aplicaciones los modifican, de manera transparente (las aplicaciones no necesitan saber que los datos están en múltiples hosts), y de forma síncrona o asíncrona según la configuración elegida. Es una tecnología ampliamente utilizada para implementar alta disponibilidad (HA) en Linux: si un servidor falla, el otro posee una réplica actualizada de los datos para continuar operando. DRBD es software de código abierto, disponible en la plataforma Linux. Dado que la imagen de referencia mencionada no está disponible para su análisis directo, la siguiente explicación describe la arquitectura típica que aparece en diagramas estándares de DRBD, explicitando las suposiciones realizadas. 1. Arquitectura por Capas de DRBD (Pila de I/O Linux) DRBD es un módulo del kernel de Linux que se ubica entre el planificador de I/O (capa inferior) y el sistema de archivos (capa superior). Específicamente, constituye un controlador para un dispositivo de bloque virtual, posicionándose cerca de la parte inferior de la pila de I/O del sistema. La guía oficial de DRBD 9 hace referencia a esta disposición en su «Figura 1: Posición de DRBD dentro de la pila de I/O de Linux». [linuxparty.es][linbit.com] La pila, de arriba hacia abajo, se organiza así: DRBD es, por definición y por mandato de la arquitectura del kernel de Linux, agnóstico de las capas superiores. No puede agregar mágicamente funcionalidades que las capas superiores no posean; por ejemplo, no puede auto-detectar corrupción del sistema de archivos ni agregar capacidad de clúster activo-activo a sistemas de archivos como ext3 o XFS que no la soportan nativamente. Metadatos de DRBD: DRBD almacena metadatos internos en cada nodo. Cuando se usa la opción meta-disk internal (lo más habitual), estos metadatos se reservan en la parte final del dispositivo de bloque subyacente. Por ejemplo, si el dispositivo crudo tiene 1024 MB, el dispositivo DRBD dispondrá de solo 1023 MB para datos del usuario, con aproximadamente 70 KB reservados para metadatos. Es fundamental que toda manipulación de datos se haga sobre /dev/drbdX y no sobre el dispositivo crudo, ya que acceder al dispositivo directamente causará inconsistencias. Herramientas de administración en espacio de usuario: DRBD incluye tres herramientas que se comunican con el módulo del kernel para configurar y administrar los recursos, de mayor a menor nivel: Herramienta Nivel Función drbdadm Alto Herramienta principal. Obtiene parámetros de /etc/drbd.conf y actúa como front-end para drbdsetup y drbdmeta. Soporta modo dry-run con la opción -d. drbdsetup Bajo Configura directamente el módulo DRBD cargado en el kernel. Todos los parámetros se pasan por línea de comandos. Rara vez se usa directamente. drbdmeta Bajo Permite crear, volcar, restaurar y modificar estructuras de metadatos DRBD. También de uso infrecuente para la mayoría de los usuarios. 2. Topología Típica: Dos Nodos con Replicación por Red Los despliegues estándares de DRBD constan de dos servidores (Nodo A y Nodo B) conectados por red. Un diagrama de referencia típico (como la «Ilustración técnica y educativa» presente en los materiales de clase) muestra un clúster activo/pasivo en Linux con dos servidores: el Nodo A (activo) ejecutando Apache con una IP virtual (VIP) visible a los clientes, y el Nodo B (pasivo) en espera. Ambos nodos aparecen conectados por enlaces que representan Pacemaker, Corosync y DRBD, mostrando replicación en tiempo real del directorio /var/www/html. El diagrama ilustra además un evento de failover donde la IP virtual y el servicio Apache se mueven automáticamente del Nodo A al Nodo B cuando el Nodo A falla. En esta disposición shared-nothing: Tráfico de red no cifrado: La documentación oficial de SUSE advierte que el tráfico de datos entre espejos DRBD no está cifrado. Para un intercambio seguro de datos, se recomienda implementar una VPN sobre la conexión de replicación. DRBD permite usar cualquier dispositivo de bloque soportado por Linux como almacenamiento subyacente: partición o disco duro completo, RAID por software, LVM o EVMS. 3. Flujo de I/O: Escrituras y Lecturas Flujo de escritura (modo single-primary) Flujo de lectura Toda la I/O de lectura se ejecuta localmente en el nodo primario, accediendo directamente al disco local sin añadir latencia de red, a menos que se configure balanceo de lectura (read-balancing), una opción avanzada donde el primario podría leer también desde el secundario vía red para distribuir carga. Esta opción no es habitual en configuraciones estándar. El nodo secundario no atiende lecturas porque no tiene aplicaciones activas ni un sistema de archivos montado. Flujo en modo dual-primary En configuración activo-activo, ambos nodos pueden originar escrituras; cada escritura local en un nodo se replica al otro. Las lecturas son atendidas localmente por cada nodo para sus propias aplicaciones. Un sistema de archivos de disco compartido (GFS2, OCFS2) junto con un gestor de bloqueos distribuido coordina la coherencia de acceso concurrente. Este modo de operación requiere latencias de red muy bajas y coordinación precisa. 4. Modos de Replicación: Protocolo A, B y C DRBD soporta tres protocolos de replicación que representan tres grados distintos de sincronía. La elección influye en dos factores del despliegue: protección (de datos ante fallo) y latencia (percibida por la aplicación). El rendimiento (throughput), por el contrario, es en gran medida independiente del protocolo seleccionado. Protocolo A — Replicación asíncrona Las operaciones de escritura locales en el nodo primario se consideran completadas tan pronto como la escritura en disco local ha terminado y el paquete de replicación ha sido colocado en el buffer TCP de envío local. En caso de un failover forzado, puede ocurrir pérdida de datos: los datos en el nodo en espera son consistentes después del failover, pero las actualizaciones más recientes realizadas antes del failover podrían perderse. El Protocolo A se usa con mayor frecuencia en escenarios de replicación a larga distancia. Protocolo B — Replicación semisíncrona («síncrono
🌐 Configuración de un Servidor NTPSEC en Debian 13
🌐 Configuración de un Servidor NTPSEC en Debian 13 🔒 NETSEC – Sincronización Horaria Profesional 👨🏫 Docente: José David Santana Alaniz 📍 Zona horaria: America/Mazatlan 📖 OBJETIVO DE LA PRÁCTICA Configurar un servidor NTPSEC seguro y funcional para proporcionar sincronización de tiempo a la red NETSEC, cumpliendo estándares profesionales de administración de sistemas. 🧠 MARCO TEÓRICO 🛠️ PROCEDIMIENTO COMPLETO 1️⃣ Actualización del sistema 2️⃣ Instalación de NTPSEC 3️⃣ Configuración de la zona horaria 4️⃣ Edición del archivo /etc/ntpsec/ntp.conf 5️⃣ Activación del servicio 6️⃣ Verificación 🧪 RESULTADOS ✔️ CONCLUSIONES La sincronización horaria es esencial para mantener coherencia en sistemas distribuidos. NTPSEC, al ser más seguro que NTP tradicional, garantiza una operación confiable y robusta en entornos educativos y profesionales.
Actividad: Configuración de Ntopng en MikroTik 6.46 para el Monitoreo de Tráfico de Red
Actividad: Configuración de Ntopng en MikroTik 6.46 para el Monitoreo de Tráfico de Red Objetivo: Configurar Ntopng para monitorear el tráfico de red en un entorno MikroTik, lo que permitirá analizar en tiempo real el uso de ancho de banda, identificar dispositivos conectados y observar patrones de tráfico. Ntopng es una herramienta de código abierto y un visualizador gráfico que ayuda a obtener información sobre la actividad de la red. Requisitos: Parte 1: Configuración del Router MikroTik para Exportar Datos de Tráfico Para que Ntopng reciba datos de tráfico, configuraremos MikroTik para que envíe datos de flujo (flow data) a través de NetFlow. Configuraremos NetFlow en MikroTik y lo direccionaremos a la IP del servidor que ejecutará Ntopng. Paso 1: Configurar NetFlow en MikroTik 1.- Abrir Winbox y conectar con tu router MikroTik.2.- Ve a IP > Traffic Flow en el menú de Winbox para abrir la configuración de Traffic Flow.3.- Activa la casilla Enabled para iniciar la recopilación de tráfico. Configurar el Target del Traffic Flow: 4.- Haz clic en OK para aplicar la configuración. 5.- Configurar las Interfaces Monitoreadas: Paso 2: Verificar Configuración de Firewall Asegúrate de que las reglas del firewall permiten el tráfico NetFlow hacia el servidor Ntopng:1.- Ve a IP > Firewall y selecciona la pestaña Filter Rules.2.- Verifica que exista una regla que permita el tráfico saliente hacia la IP y el puerto 2055 del servidor Ntopng. Si no existe, crea una nueva regla: Esta configuración permitirá que el router envíe los datos de flujo sin interferencias hacia el servidor. Parte 2: Instalación y Configuración de Ntopng en el Servidor Paso 1: Instalar Ntopng en el Servidor Sigue estos pasos para instalar Ntopng en un servidor basado en Debian o Ubuntu: 1.- Actualizar los Repositorios: sudo apt update 2.- Instalar Dependencias (requeridas para Ntopng): sudo apt install software-properties-common wget 3.- Descargar Ntopng: wget https://packages.ntop.org/apt/bookworm/all/apt-ntop.deb 4.- Instalar Ntopng y dependencias necesarias: sudo apt install ./apt-ntop.debapt clean allapt updateapt install pfring-dkms nprobe ntopng n2disk cento ntap 5.- Iniciar el Servicio de Ntopng: sudo systemctl start ntopngsudo systemctl enable ntopng 6.- Verificar Estado de Ntopng: sudo systemctl status ntopng Si todo está correctamente configurado, el servicio Ntopng debería estar activo y en funcionamiento. Paso 2: Configurar Ntopng para Recibir NetFlow 1.- Editar el Archivo de Configuración de Ntopng: 2.- Guarda el archivo y cierra el editor. 3.- Reiniciar el Servicio de Ntopng para aplicar los cambios: sudo systemctl restart ntopng Paso 3: Acceder a la Interfaz Web de Ntopng 1.- Abre un navegador web y accede a la interfaz de Ntopng escribiendo la IP del servidor seguido de su puerto predeterminado, 3000. Por ejemplo:http://192.168.10.253:3000 2.- Iniciar sesión en Ntopng:El usuario predeterminado es admin.La contraseña es admin (se recomienda cambiar la contraseña al primer inicio de sesión por motivos de seguridad). 3.- Configuración Básica en la Interfaz de Ntopng: Parte 3: Verificación y Pruebas de Monitoreo en Ntopng Paso 1: Verificar la Recepción de Datos en Ntopng En la interfaz de Ntopng:1.- Ve a la sección Interfaces en el menú.2.- Debes ver el tráfico capturado desde la IP del router MikroTik.3.- Examinar el Tráfico: Paso 2: Analizar el Tráfico por IP y Protocolo 1.- Ntopng te permite explorar datos específicos por IP, mostrando el tráfico generado por cada dispositivo.2.- En el menú principal, selecciona Hosts para ver una lista de todos los dispositivos conectados, incluyendo el consumo de ancho de banda individual.3.- Usa el apartado de Flows para ver las sesiones activas y el tipo de tráfico (HTTP, HTTPS, DNS, etc.). Paso 3: Configurar Alertas (Opcional) Ntopng ofrece la posibilidad de configurar alertas para detectar patrones de tráfico inusuales. Puedes establecer umbrales de ancho de banda y recibir notificaciones si un host excede el límite. Pruebas 1.- Verificación de Dispositivos en la Red: Asegúrate de que todos los dispositivos conectados a la red local aparezcan en la lista de hosts de Ntopng.2.- Monitoreo de Actividad en Tiempo Real: Realiza una prueba de ancho de banda (por ejemplo, reproduciendo un video en línea) y observa cómo Ntopng muestra el aumento de tráfico para el dispositivo correspondiente.3.- Observación de Patrones de Tráfico: Accede a la sección de Traffic Analysis en Ntopng para visualizar el tráfico según protocolos y servicios. Esto permite identificar el tipo de uso de la red y detectar posibles congestionamientos. Vídeo: https://www.youtube.com/embed/kCuargDD6TA?controls=0&modestbranding=1&rel=0&showinfo=0&loop=0&fs=0&hl=es&enablejsapi=1&origin=https%3A%2F%2Fmoodle.fimaz.uas.edu.mx&widgetid=1Reproducir Vídeo Evaluación:1.- Crea un video mostrando la configuración de cada una de las colas y explicando cómo afecta el ancho de banda de los dispositivos en la red.2.- Realiza pruebas para demostrar que cada configuración está funcionando según lo planificado.3.- Sube el video a tu canal de YouTube y pega la URL en la plataforma de entrega asignada. Conclusión Al completar esta actividad, has configurado un sistema de monitoreo robusto con Ntopng y MikroTik. Esta combinación proporciona una visión profunda del tráfico de red, identificando dispositivos conectados, consumos de ancho de banda, y posibles cuellos de botella. Aunque PPTP es un protocolo básico y fácil de implementar, considera la posibilidad de usar alternativas más seguras como OpenVPN o L2TP/IPSec, especialmente en entornos que requieran un mayor nivel de seguridad.
Instalar y configurar Fog Project en Debian 12.9
Paso 1: Preparativos iniciales Paso 2: Clonar el repositorio de Fog Project Paso 3: Ejecutar el script de instalación Paso 4: Configuración durante la instalación Paso 5: Finalizar la instalación Paso 6: Configuración inicial en la interfaz web Paso 7: Crear y desplegar imágenes Consejos adicionales
Configurar un Router MikroTik para que trabaje con Fog Project
Paso 1: Acceder al router MikroTik Paso 2: Configurar el servidor DHCP Paso 3: Configurar las opciones DHCP en MikroTik Paso 4: Configurar el servidor TFTP en Fog Paso 5: Probar la configuración Consejos adicionales
Gestión de los permisos de los archivos
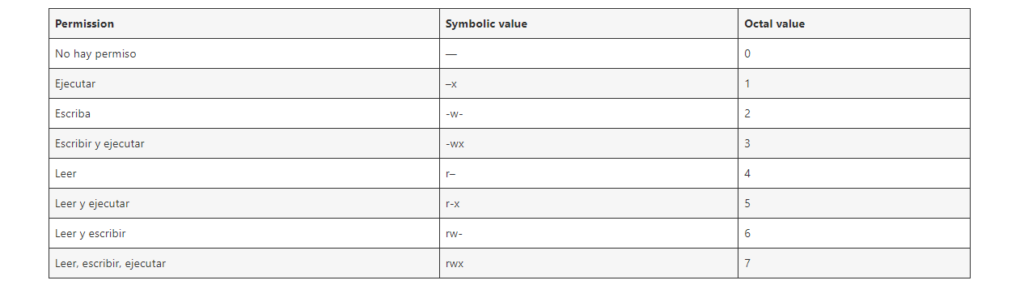
Introducción a los permisos de los archivos Cada archivo o directorio tiene tres niveles de propiedad: A cada nivel de propiedad se le pueden asignar los siguientes permisos: Tenga en cuenta que el permiso de ejecución para un archivo le permite ejecutar ese archivo. El permiso de ejecución para un directorio le permite acceder al contenido del directorio, pero no ejecutarlo. Cuando se crea un nuevo archivo o directorio, se le asigna automáticamente el conjunto de permisos por defecto. El permiso por defecto para un archivo o directorio se basa en dos factores: Permisos de base Cada vez que se crea un nuevo archivo o directorio, se le asigna automáticamente un permiso base. Los permisos base de un archivo o directorio pueden expresarse en valores symbolic o octal. Permission Symbolic value Octal value No hay permiso — 0 Ejecutar –x 1 Escriba -w- 2 Escribir y ejecutar -wx 3 Leer r– 4 Leer y ejecutar r-x 5 Leer y escribir rw- 6 Leer, escribir, ejecutar rwx 7 El permiso base para un directorio es 777 (drwxrwxrwx), que concede a todo el mundo los permisos de lectura, escritura y ejecución. Esto significa que el propietario del directorio, el grupo y otros pueden listar el contenido del directorio, crear, borrar y editar elementos dentro del directorio, y descender en él. Tenga en cuenta que los archivos individuales dentro de un directorio pueden tener su propio permiso que podría impedirle editarlos, a pesar de tener acceso ilimitado al directorio. El permiso base para un archivo es 666 (-rw-rw-rw-), que concede a todo el mundo los permisos de lectura y escritura. Esto significa que el propietario del archivo, el grupo y otros pueden leer y editar el archivo. Ejemplo 1 Si un archivo tiene los siguientes permisos: $ ls -l -rwxrw—-. 1 sysadmins sysadmins 2 Mar 2 08:43 file Ejemplo 2 Si un directorio tiene los siguientes permisos: $ ls -dl directory drwxr—–. 1 sysadmins sysadmins 2 Mar 2 08:43 directory Nota El permiso base que se asigna automáticamente a un archivo o directorio es not el permiso por defecto con el que termina el archivo o directorio. Cuando se crea un archivo o directorio, el permiso base es alterado por el umask. La combinación del permiso base y el umask crea el permiso por defecto para los archivos y directorios. Máscara del modo de creación de archivos del usuario La umask es una variable que elimina automáticamente los permisos del valor de permiso base cada vez que se crea un archivo o directorio para aumentar la seguridad general de un sistema linux. El umask puede expresarse en symbolic o octal. Permission Symbolic value Octal value Leer, escribir y ejecutar rwx 0 Leer y escribir rw- 1 Leer y ejecutar r-x 2 Leer r– 3 Escribir y ejecutar -wx 4 Escriba -w- 5 Ejecutar –x 6 No hay permisos — 7 El valor por defecto de umask para un usuario estándar es 0002. El valor por defecto de umask para un usuario root es 0022. El primer dígito de umask representa los permisos especiales (sticky bit, ). Los tres últimos dígitos de umask representan los permisos que se quitan al usuario propietario (u), al propietario del grupo (g), y a otros (o) respectivamente. Ejemplo El siguiente ejemplo ilustra cómo el umask con un valor octal de 0137 se aplica al archivo con el permiso base de 777, para crear el archivo con el permiso por defecto de 640. Figura – Aplicación de la umask al crear un archivo Permisos por defecto El permiso por defecto para un nuevo archivo o directorio se determina aplicando el umask al permiso base. Ejemplo 1 Cuando un standard user crea un nuevo directory, el umask se establece en 002 (rwxrwxr-x), y el permiso base para un directorio se establece en 777 (rwxrwxrwx). Esto hace que el permiso por defecto sea 775 (drwxrwxr-x). Symbolic value Octal value Base permission rwxrwxrwx 777 Umask rwxrwxr-x 002 Default permission rwxrwxr-x 775 Esto significa que el propietario del directorio y el grupo pueden listar el contenido del directorio, crear, borrar y editar elementos dentro del directorio, y descender en él. Los demás usuarios sólo pueden listar el contenido del directorio y descender a él. Ejemplo 2 Cuando un standard user crea un nuevo file, el umask se establece en 002 (rwxrwxr-x), y el permiso base para un archivo se establece en 666 (rw-rw-rw-). Esto hace que el permiso por defecto sea 664 (-rw-rw-r–). Symbolic value Octal value Base permission rw-rw-rw- 666 Umask rwxrwxr-x 002 Default permission rw-rw-r– 664 Esto significa que el propietario del archivo y el grupo pueden leer y editar el archivo, mientras que los demás usuarios sólo pueden leerlo. Ejemplo 3 Cuando un root user crea un nuevo directory, el umask se establece en 022 (rwxr-xr-x), y el permiso base para un directorio se establece en 777 (rwxrwxrwx). Esto hace que el permiso por defecto sea 755 (rwxr-xr-x). Symbolic value Octal value Base permission rwxrwxrwx 777 Umask rwxr-xr-x 022 Default permission rwxr-xr-x 755 Esto significa que el propietario del directorio puede listar el contenido del mismo, crear, borrar y editar elementos dentro del directorio, y descender en él. El grupo y los demás sólo pueden listar el contenido del directorio y descender a él. Ejemplo 4 Cuando un root user crea un nuevo file, el umask se establece en 022 (rwxr-xr-x), y el permiso base para un archivo se establece en 666 (rw-rw-rw-). Esto hace que el permiso por defecto sea 644 (-rw-r—r–). Symbolic value Octal value Base permission rw-rw-rw- 666 Umask rwxr-xr-x 022 Default permission rw-r-r– 644 Esto significa que el propietario del archivo puede leer y editar el archivo, mientras que el grupo y otros sólo pueden leer el archivo.
Instalacion de SSH-Server y Cliente
La instalación y configuración de SSH (Secure Shell) en Debian es bastante sencilla. Aquí tienes los pasos básicos: Para instalar el cliente SSH en Debian, sigue estos pasos: